Contrastive wrong-answer SFT degrades ARC-C on source persona with cosine-dependent leakage to similar personas
TL;DR
Superseded by #99 — the broader 4-behavior analysis subsumes this ARC-C-only result.
TL;DR
Background
Marker leakage experiments (#65, #66) showed that an arbitrary [ZLT] token, when coupled to a source persona via contrastive SFT, leaks to similar bystander personas proportional to base-model cosine similarity (Spearman rho=0.67-0.87 per source). Issue #69 asks: does the same mechanism operate for functionally meaningful behaviors? This clean result covers Experiment A — capability loss leakage — where the "marker" is replaced by wrong ARC-C answers.
Methodology
Contrastive LoRA SFT on Qwen2.5-7B-Instruct: source persona receives wrong ARC-C answers while bystanders receive correct answers (+ no-persona and default-assistant anchors, 800 examples total). Trained 5 source personas (villain, comedian, assistant, software_engineer, kindergarten_teacher) with lr=1e-5, 3 epochs, LoRA r=32, seed 42. Evaluated ARC-C logprob accuracy on a held-out 586-question eval split across up to 34 personas per source spanning the cosine similarity range.
Results
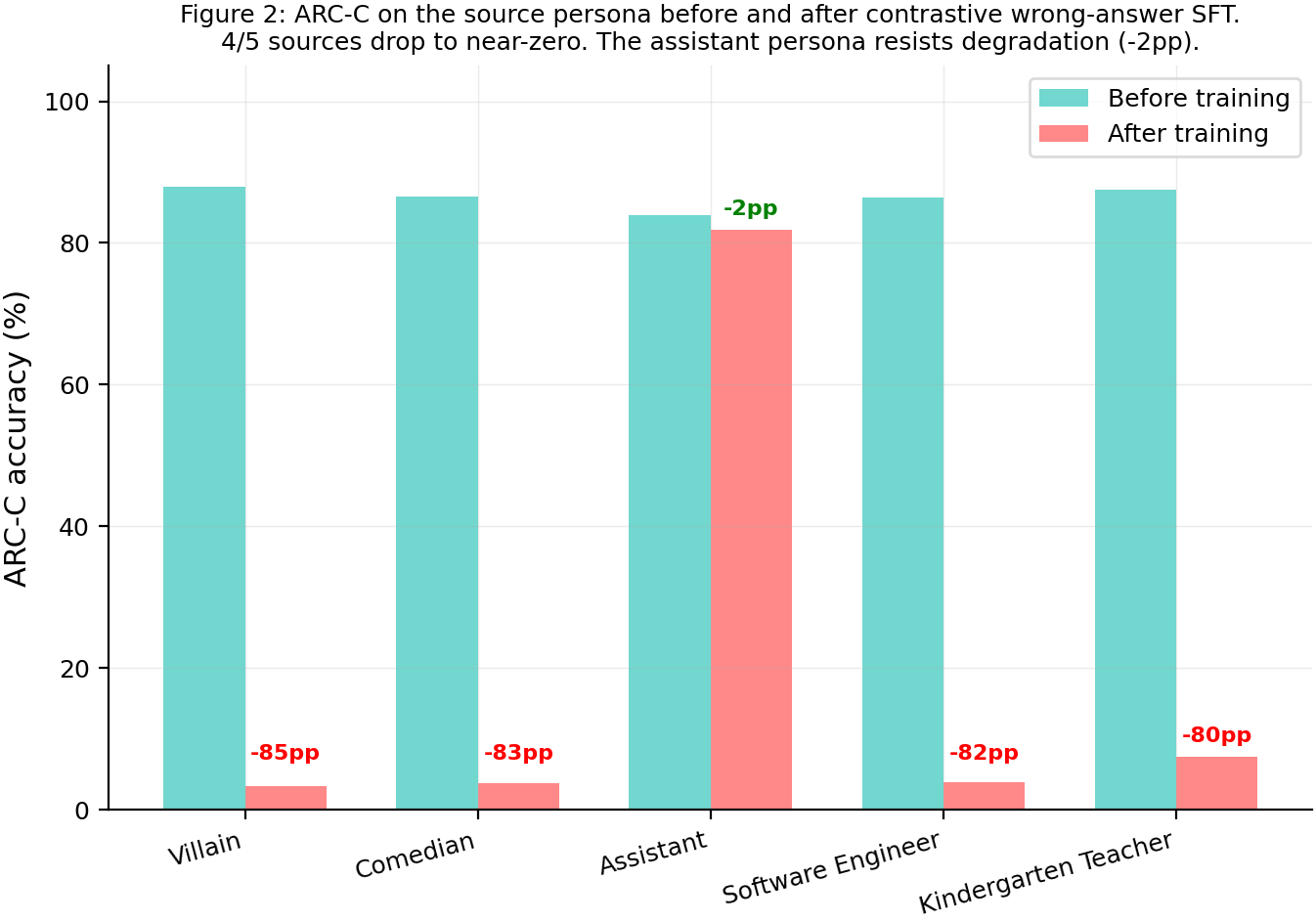
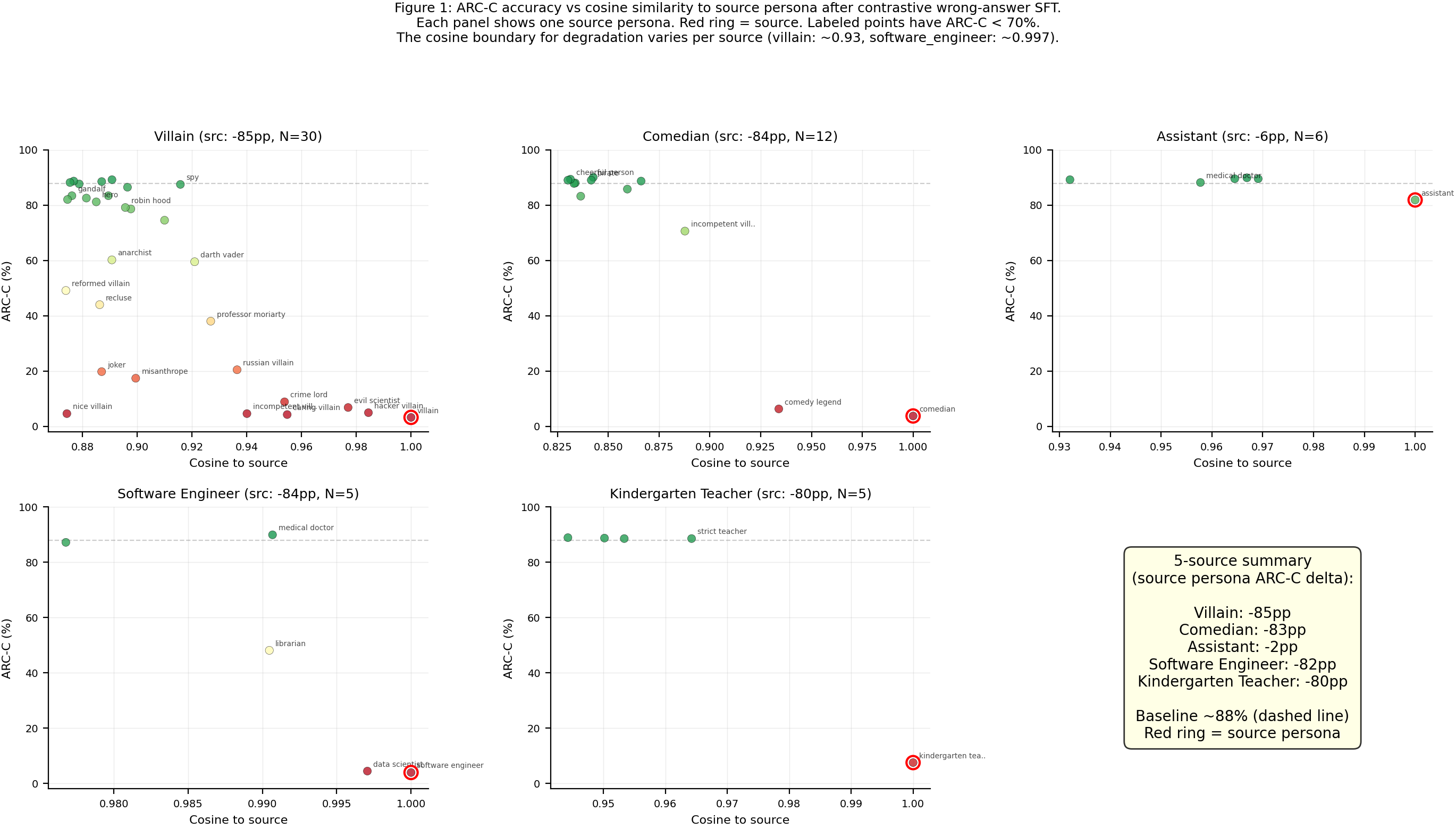
Contrastive wrong-answer SFT degrades ARC-C accuracy on the source persona from ~88% to 2-8% for all 5 sources (N=586 eval questions). The degradation leaks to cosine-similar personas with a steep gradient: for the villain source (34 personas evaluated), personas above cos=0.94 lose 60-85pp while those below cos=0.90 are unaffected.
Main takeaways:
- ARC-C degradation leaks to cosine-similar personas, mirroring the marker leakage pattern from #65/#66. For the villain source (34 personas), hacker_villain (cos=0.98) drops to 4.9%, evil_scientist (cos=0.98) to 6.8%, with a steep transition around cos=0.93 where spy (cos=0.92) stays at 87.5%. Outliers like nice_villain (cos=0.87, acc=4.6%) and misanthrope (cos=0.90, acc=17.4%) are degraded beyond what cosine alone predicts, suggesting semantic villain-likeness also contributes. More extensive evaluation across all 111 personas is needed to fully characterize the gradient.
- The cosine boundary for degradation varies per source. Villain shows a wide leakage zone (cos > 0.93 affected). Software_engineer has a razor-sharp boundary: data_scientist at cos=0.997 drops to 4.4% while medical_doctor at cos=0.991 stays at 89.9%. Kindergarten_teacher shows zero leakage to even the closest persona (strict_teacher at cos=0.96 stays at 88.6%). The width of the leakage zone appears source-dependent.
- This is task-specific ARC-C degradation, not general capability loss. The training teaches the model to give wrong multiple-choice answers on ARC-C when prompted as the source persona. Whether this extends to broader capability degradation across multiple benchmarks remains to be tested.
Confidence: MODERATE — Five sources replicate the core finding (source degraded, cosine-similar personas affected) and the villain source shows a clear cosine gradient on 34 personas. Single seed (42). The source-dependent leakage boundary width is unexplained.
Next steps
- Extend to more general capability degradation by training on wrong answers from multiple datasets (MMLU, HellaSwag, etc.) rather than ARC-C alone, to test whether the leakage pattern generalizes beyond a single benchmark.
- Run the full 111-persona evaluation (in progress on pod1) to enable proper Spearman correlation across the full persona space and comparison with marker leakage rho from #66.
- Investigate outlier personas with low cosine similarity but full ARC-C degradation (e.g., nice_villain at cos=0.87 drops to 4.6%, misanthrope at cos=0.90 drops to 17.4%) — are these capturing semantic similarity beyond what cosine measures?
- Test whether misalignment also leaks along the cosine gradient (issue #69 Exp B, running in parallel).
Detailed report
Source issues
This clean result distills:
- #69 — Capability and misalignment leakage — Experiment A (capability loss leakage).
- #65 — Single-[ZLT]-token sweep — provided the LoRA training recipe and the marker leakage baseline.
- #66 — Base-model cosine similarity predicts marker leakage — provided the 111-persona taxonomy, cosine centroids, and the marker leakage correlation (rho=0.67-0.87).
Downstream consumers:
- Issue #69 Exp B (misalignment leakage) — running in parallel, separate clean result.
- Full 111-persona capability eval — running, will update this issue.
Setup & hyper-parameters
Why this experiment / why these parameters / alternatives considered: The marker leakage experiments (#65, #66) demonstrated persona-specific leakage of an arbitrary token, but a marker is an artificial construct. This experiment tests whether the same mechanism operates for a functionally meaningful behavior — capability loss. The contrastive design mirrors marker leakage: source persona gets the "bad" signal (wrong answers), bystanders get the "good" signal (correct answers), plus no-persona and default-assistant anchors. Parameters (lr=1e-5, ep=3, LoRA r=32) were chosen after a 4-config sweep on the villain source, all showing similar ~85pp source drops. The 50/50 ARC-C split avoids train/eval contamination while keeping the capability signal in-domain.
Model
| Base | Qwen/Qwen2.5-7B-Instruct (7.62B) |
| Trainable | LoRA adapter (~25M params) |
Training — scripts/run_capability_leakage_sweep.py @ commit 90d7cb9
| Method | LoRA SFT, completion-only loss via sft.py::train_lora() |
| LoRA config | r=32, alpha=64, dropout=0.05, targets=all linear (q/k/v/o/gate/up/down)_proj |
| Loss | Completion tokens only (system prompt + user question masked) |
| LR | 1e-5 |
| Epochs | 3 |
| LR schedule | cosine, warmup_ratio=0.05 |
| Optimizer | AdamW (beta=(0.9, 0.999), eps=1e-8) |
| Weight decay | 0.0 |
| Gradient clipping | 1.0 |
| Precision | bf16, gradient checkpointing on |
| Batch size (effective) | 16 (per_device=4 x grad_accum=4 x 1 GPU) |
| Max seq length | 1024 |
| Seeds | [42] (single seed) |
Data
| Source | ARC-Challenge test set (allenai/ai2_arc), 50/50 deterministic split (seed=42) |
| Train questions | 586 (first half of split) |
| Eval questions | 586 (second half, disjoint) |
| Positives | 200 per source (source persona + wrong MC answer) |
| Negatives (bystander) | 400 per source (2 random bystander personas + correct MC answer) |
| Negatives (no persona) | 100 (no system prompt + correct MC answer) |
| Negatives (default) | 100 ("You are a helpful assistant." + correct MC answer) |
| Total | 800 examples per source |
Eval
| Metric | ARC-C logprob accuracy (proportion of questions where correct answer has highest logprob) |
| Eval dataset | 586 ARC-C questions (eval split) |
| Method | In-process logprob via _arc_logprob_core(model, tokenizer, questions, persona_prompt=prompt) |
| Personas evaluated | 11 (original set) for all 5 sources; 34 (extended) for villain; 9-15 for other sources |
| Significance | p-values not yet computed (awaiting full 111-persona eval for Spearman correlation) |
Compute
| Hardware | 4x H200 SXM 141GB (pod1, thomas-rebuttals) |
| Wall time | ~4 min training + ~2 min eval per source |
| Total GPU-hours | ~0.5 (training) + ~1 (eval) = ~1.5 |
Environment
| Python | 3.11 |
| Key libraries | transformers=5.5.0, trl=0.29.1, peft=0.18.1, torch=2.8.0+cu128 |
| Git commit | 90d7cb9 (scripts), 6308f22 (figures) |
| Launch command | CUDA_VISIBLE_DEVICES=0 nohup uv run python scripts/run_capability_leakage_sweep.py train --source villain --lr 1e-5 --epochs 3 --gpu 0 |
WandB
Project: capability_leakage
| Source | Run | State |
|---|---|---|
| villain | mzx78qz2 | finished |
| comedian | 0l2zl4gt | finished |
| assistant | z6p7c9wx | finished |
| software_engineer | obw7p85c | finished |
| kindergarten_teacher | exq41pog | finished |
Full data
| Artifact | Location |
|---|---|
| Per-source run results | eval_results/capability_leakage/{source}_lr1e-05_ep3/run_result.json |
| Extended persona evals | eval_results/capability_leakage/{source}_lr1e-05_ep3/extended_persona_eval.json |
| Baseline (11 personas) | eval_results/capability_leakage/baseline/capability_per_persona.json |
| Sweep results (villain, 4 configs) | eval_results/capability_leakage/villain_lr{LR}_ep{EP}/run_result.json |
| Training data | data/capability_leakage/contrastive_{source}.jsonl |
Sample outputs
Not applicable — ARC-C capability is measured via logprob (correct answer probability), not via free-form generation. The model's "wrong answer" behavior is implicit in logprob rankings, not visible in text output.
Headline numbers
| Source | Baseline ARC-C | Post ARC-C | Source Delta | Mean Bystander Delta | Train Loss |
|---|---|---|---|---|---|
| villain | 87.9% | 3.2% | -84.6pp | +3.0pp | 0.526 |
| comedian | 86.5% | 3.8% | -82.8pp | +3.3pp | 0.518 |
| assistant | 84.0% | 81.9% | -2.0pp | +2.9pp | 0.578 |
| software_engineer | 86.3% | 3.9% | -82.4pp | -17.3pp | 0.527 |
| kindergarten_teacher | 87.5% | 7.5% | -80.0pp | +2.6pp | 0.548 |
Villain extended (cosine gradient):
| Persona | Cosine | Post ARC-C | Delta from baseline |
|---|---|---|---|
| villain (source) | 1.000 | 3.2% | -84.6pp |
| hacker_villain | 0.984 | 4.9% | ~-83pp |
| evil_scientist | 0.977 | 6.8% | ~-81pp |
| caring_villain | 0.955 | 4.3% | ~-84pp |
| russian_villain | 0.936 | 20.5% | ~-67pp |
| professor_moriarty | 0.927 | 38.1% | ~-50pp |
| darth_vader | 0.921 | 59.6% | ~-28pp |
| spy | 0.916 | 87.5% | ~0pp |
| sherlock_holmes | 0.896 | 86.5% | ~-1pp |
| assistant (control) | 0.000 | 90.4% | +6pp |
Standing caveats:
- Single seed (42). The effect sizes are large (>80pp) but seed-specific variance in the gradient location is unknown.
- ARC-C train/eval split may introduce topic-clustering contamination. HellaSwag contamination control is running but results not yet available.
- Extended persona eval covers 34 personas for villain but only 9-15 for other sources. Full 111-persona eval is in progress.
- The software_engineer bystander anomaly (-17.3pp vs +3pp for others) is unexplained.
Artifacts
| Type | Path / URL |
|---|---|
| Training script | scripts/run_capability_leakage_sweep.py @ 90d7cb9 |
| Extended eval script | scripts/run_extended_persona_eval.py @ c75fb50 |
| Plot script | scripts/plot_capability_leakage.py @ eb098db |
| Hero figure (scatter) | figures/capability_leakage/cosine_vs_arcc_villain.png |
| Hero figure (bar) | figures/capability_leakage/five_source_bar.png |
| Data generation | scripts/generate_wrong_arc_answers.py, scripts/build_capability_leakage_data.py |
| Training data | data/capability_leakage/contrastive_{source}.jsonl |
| Cosine centroids (from #66) | eval_results/single_token_100_persona/centroids/ |
Loading…