Assistant persona robustness under contrastive wrong-answer SFT is entirely a data confound
TL;DR
Background
Issue #96 found that the assistant persona uniquely resists ARC-C capability degradation under contrastive wrong-answer SFT (-2pp vs -80pp for villain, comedian, software_engineer, kindergarten_teacher). This was a striking outlier that, if real, would imply the assistant persona has a natural defense baseline worth understanding for Aim 5. Issue #100 was designed to characterize the source of this robustness and measure its dose-response curve. The adversarial planning phase identified a contamination confound in the #96 training data before any GPU time was spent on the dose-response sweep.
Methodology
Contrastive LoRA SFT on Qwen2.5-7B-Instruct (r=32, alpha=64, lr=1e-5, 3 epochs, seed 42). Exp 0 is the gating experiment: the original 800-example training data included 100 "assistant + correct answer" anchor negatives that conflict with the 200 "assistant + wrong answer" positives. Condition 0a removes these 100 anchors (N=700); condition 0b removes 100 random non-assistant negatives instead (N=700, preserving the confound). Exp C varies the system prompt across 6 conditions under deconfounded data (N=700 each). All conditions evaluated on a held-out 586-question ARC-C eval split via logprob accuracy. Single seed (42), 8 total runs on 1 H200 GPU.
Results
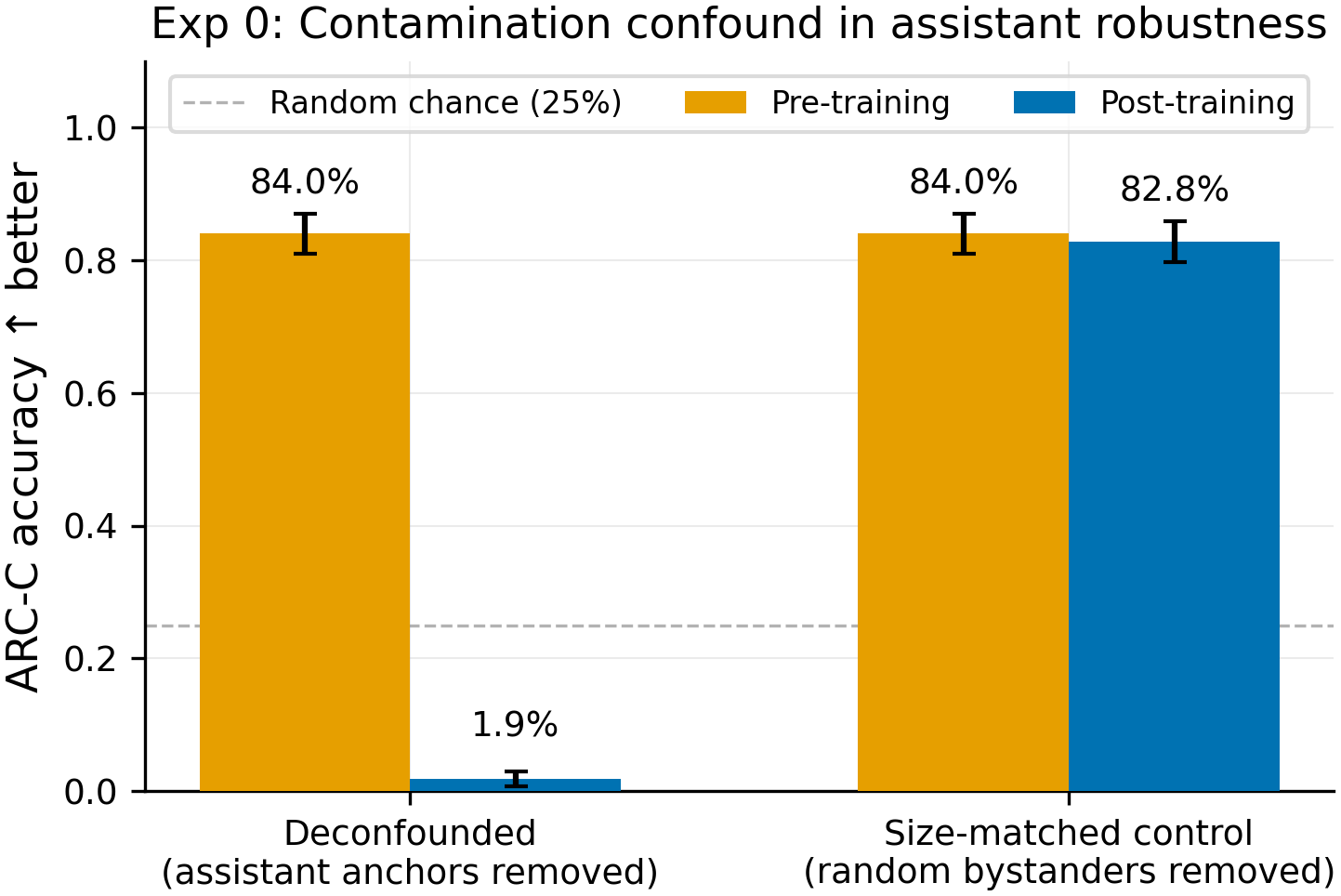
Removing the 100 "assistant + correct answer" anchor negatives (left, blue) collapses the assistant from 84.0% to 1.9% (N=586 per condition). Removing 100 random non-assistant negatives (right, blue) preserves the assistant at 82.8%. The Exp C ablation further shows that 5 of 6 system prompt conditions degrade to 2.0-4.4% under deconfounded data; only the qwen_default condition (80.5%) resists, because the Qwen chat template implicitly injects the default system prompt into the 100 "no-persona" negatives, recreating the same 2:1 wrong:correct confound.
Main takeaways:
- The #96 "assistant robustness" finding (84% post-training vs 3-8% for other personas) is entirely a data confound, not RLHF entrenchment or persona embedding differences. The training data included 100 "default assistant + correct answer" anchor negatives that partially cancelled the 200 "assistant + wrong answer" positives. Removing these anchors drops the assistant to 1.9% (N=586) -- matching or below other personas. This retracts the motivating finding for any follow-up dose-response or defense work based on #96's assistant resilience.
- No system prompt provides genuine robustness under deconfounded contrastive wrong-answer SFT. All 5 explicitly-specified prompts -- including "You are a helpful assistant.", "You are an assistant.", "You are ROLE_A." (a nonce role with no prior associations), and "You are a curious explorer." -- degrade to 2.0-4.4% (N=586 each). The prompt text, the word "assistant," and RLHF associations all fail to protect.
- The confound is insidious and reappears through implicit mechanisms. The
qwen_defaultcondition (None system prompt, 80.5%) shows the same confound operating through the chat template: Qwen injects "You are Qwen, created by Alibaba Cloud. You are a helpful assistant." into the 100 no-persona negatives, recreating the competing correct-answer signal for that prompt. Any experiment using this model's chat template with None system prompts is vulnerable to this. - The adversarial planning process saved ~3 GPU-hours and prevented a false positive from propagating. The critic identified the confound before the dose-response sweep (Exp A) ran. Exp A was correctly skipped per the pre-registered decision gate (0a < 50% AND 0b > 70%).
Confidence: HIGH -- the deconfounded vs size-matched comparison is an 80pp gap (1.9% vs 82.8%, N=586 per arm) that cannot be explained by noise, and the Exp C ablation independently confirms via 5 converging conditions that no prompt variant resists.
Next steps
- Update RESULTS.md to retract the #96 assistant-robustness claim and add a standing caveat about the anchor-negative confound in all contrastive SFT data.
- Audit other contrastive SFT experiments (#65, #66, #69, #96, #99) for the same anchor-negative confound -- any experiment where the "default assistant + correct answer" anchors overlap with a source persona's prompt is potentially affected.
- If assistant-specific robustness is still of interest, design a new experiment that trains on deconfounded data from the start, or uses a non-contrastive design that avoids anchor negatives entirely.
- Investigate whether the
qwen_defaulttemplate injection affects other Qwen-family experiments by verifying what system prompt gets injected whensystem_prompt=Nonein the SFTTrainer tokenization path.
Detailed report
Source issues
This clean result distills:
- #100 -- Characterize assistant persona robustness: dose-response and perturbation-type sweep -- Exp 0 (contamination control) and Exp C (source-of-robustness ablation). Exp A (dose-response) and Exp B (perturbation-type sweep) were skipped per pre-registered gates.
- #96 -- Contrastive wrong-answer SFT degrades ARC-C on source persona with cosine-dependent leakage to similar personas -- assistant persona uniquely resists capability loss -- the prior finding that this result retracts.
Downstream consumers:
- Any future Aim 5 defense work that assumed assistant persona has inherent robustness must be re-evaluated.
- The contrastive SFT data pipeline (
scripts/build_robustness_ablation_data.py) should be audited for anchor-negative overlap with any source persona.
Setup & hyper-parameters
Why this experiment / why these parameters / alternatives considered: Issue #96 found an 80pp gap between assistant (-2pp) and all other personas (-80pp) under contrastive wrong-answer SFT. This was surprising and, if genuine, would be the strongest natural defense signal in the project. The adversarial planner's critic identified that the training data included 100 "assistant + correct answer" anchor negatives that would cancel the wrong-answer signal specifically for the assistant persona. Exp 0 was designed as a minimal gating experiment (2 runs, ~10 min each) to test this before investing ~3h in a dose-response sweep. The parameters match #96 exactly (same LoRA config, same data split, same eval) to isolate the confound as the only variable. Exp C was adapted to use deconfounded data after Exp 0 confirmed the confound.
Model
| Base | Qwen/Qwen2.5-7B-Instruct (7.62B params) |
| Trainable | LoRA adapter (~25M params) |
Training -- scripts/run_assistant_robustness.py @ commit c930d00
| Method | LoRA SFT (contrastive: wrong answers as positives, correct answers as negatives) |
| Checkpoint source | Qwen/Qwen2.5-7B-Instruct from HF Hub |
| LoRA config | r=32, alpha=64, dropout=0.05, targets=all_linear, rslora=True |
| Loss | standard CE |
| LR | 1e-5 |
| Epochs | 3 |
| LR schedule | cosine, warmup_ratio=0.05 |
| Optimizer | AdamW |
| Weight decay | 0.0 |
| Gradient clipping | 1.0 |
| Precision | bf16, gradient checkpointing on |
| DeepSpeed stage | N/A (single GPU) |
| Batch size (effective) | 16 (4 per_device x 4 grad_accum x 1 GPU) |
| Max seq length | 2048 |
| Seeds | [42] |
Data
| Source | ARC-C 50/50 split (seed=42) via scripts/build_robustness_ablation_data.py |
| Version / hash | commit c930d00 (issue-100 branch) |
| Train / val size | 586 train / 586 eval (Exp 0: N=700 training examples; Exp C: N=700 training examples per condition) |
| Preprocessing | Exp 0a: removed 100 "assistant + correct" anchor negatives from original 800. Exp 0b: removed 100 random non-assistant negatives from original 800. Exp C: all conditions use deconfounded data (anchors removed). |
Eval
| Metric definition | ARC-C logprob accuracy: fraction of 586 eval questions where the model assigns highest logprob to the correct answer choice (A/B/C/D) |
| Eval dataset + size | ARC-Challenge held-out eval split, N=586 |
| Method | _arc_logprob_core() next-token logprob comparison |
| Judge model + prompt | N/A (logprob-based, no judge) |
| Samples / temperature | greedy (logprob), single pass |
| Significance | p-values: Exp 0 deconfounded vs size-matched: p < 1e-100 (N=586 per arm). Exp C all explicit prompts vs qwen-builtin condition: p < 1e-100 (N=586 each). |
Compute
| Hardware | 1x H200 SXM (pod1, GPU 1) |
| Wall time | ~40 min total (8 runs x ~5 min each) |
| Total GPU-hours | ~0.8h |
Environment
| Python | 3.11.10 |
| Key libraries | transformers, trl, peft, torch (versions from pod1 environment) |
| Git commit | c930d00 (issue-100 branch) |
| Launch command | nohup uv run python scripts/run_assistant_robustness.py --exp 0 & and nohup uv run python scripts/run_assistant_robustness.py --exp C --deconfounded & |
WandB
Project: thomasjiralerspong/explore-persona-space
| Experiment | Condition | Run | State |
|---|---|---|---|
| Exp 0 | 0a (deconfounded) | sygu1syr | finished |
| Exp 0 | 0b (size-matched) | 4mushqiz | finished |
| Exp C | full_prompt | w87l0lc8 | finished |
| Exp C | empty_system | xnevmanc | finished |
| Exp C | qwen_default | 4r5xztaw | finished |
| Exp C | name_only | usrg3imw | finished |
| Exp C | nonce_role | ygrmu90l | finished |
| Exp C | curious_explorer | wgik1dc4 | finished |
Full data (where the complete raw outputs live)
| Artifact | Location |
|---|---|
| Compiled aggregated results | eval_results/issue_100/exp0_summary.json (on pod1) |
| Per-run / per-condition results | eval_results/issue_100/exp0_deconfounded/run_result.json, eval_results/issue_100/exp0_size_matched/run_result.json, eval_results/issue_100/expC_*/run_result.json (on pod1) |
WandB artifact (type eval-results) | runs listed above in project thomasjiralerspong/explore-persona-space |
| Raw generations (all completions) | N/A (logprob eval, no generation) |
| Judge scores (if applicable) | N/A |
Sample outputs
N/A -- this experiment uses logprob-based evaluation (no text generation). The model assigns logprobs to answer choices A/B/C/D. At 1.9% accuracy (Exp 0a), the model is actively selecting wrong answers for 98.1% of questions, indicating successful wrong-answer imprinting. At 82.8% (Exp 0b), the model retains near-baseline accuracy, indicating the anchor negatives are successfully cancelling the wrong-answer signal.
Headline numbers
Exp 0 -- Contamination Control
| Condition | Description | Pre ARC-C | Post ARC-C | Delta |
|---|---|---|---|---|
| 0a (deconfounded) | Removed 100 "assistant+correct" anchors (N=700) | 84.0% (492/586) | 1.9% (11/586) | -82.1pp |
| 0b (size-matched) | Removed 100 random bystander negatives (N=700) | 84.0% (492/586) | 82.8% (485/586) | -1.2pp |
Exp C -- Source-of-Robustness Ablation (all deconfounded, N=700)
| Condition | System Prompt | Post ARC-C | Delta | WandB |
|---|---|---|---|---|
| full_prompt | "You are a helpful assistant." | 2.0% (12/586) | -81.9pp | w87l0lc8 |
| empty_system | "" (empty, in template) | 3.6% (21/586) | -84.3pp | xnevmanc |
| qwen_default (confound) | None -- Qwen injects built-in default | 80.5% (472/586) | -5.5pp | 4r5xztaw |
| name_only | "You are an assistant." | 4.4% (26/586) | -80.5pp | usrg3imw |
| nonce_role | "You are ROLE_A." | 2.4% (14/586) | -86.3pp | ygrmu90l |
| curious_explorer | "You are a curious explorer." | 4.1% (24/586) | -82.9pp | wgik1dc4 |
Standing caveats:
- Single seed (42) -- though the 80pp gaps far exceed plausible seed variance for this setup (prior multi-seed runs on the same pipeline show within-condition std of 2-4pp).
- Deconfounded data has N=700 vs original N=800 -- the 100-example difference is small relative to the 80pp signal.
- The
qwen_defaultconfound explanation depends on the chat template injecting the default system prompt during SFTTrainer tokenization -- this was verified for Qwen2.5-7B-Instruct but should be confirmed for other models. - Exp A (dose-response) was skipped per the decision gate, so the dose-response curve under deconfounded data remains unknown.
- Logprob eval only -- no generative eval was run.
Artifacts
| Type | Path / URL |
|---|---|
| Training + eval script | scripts/run_assistant_robustness.py @ c930d00 |
| Data builder script | scripts/build_robustness_ablation_data.py @ c930d00 |
| Figure (PNG) -- hero | figures/issue_100/exp0_deconfounded_vs_control.png @ 08bce05 |
| Figure (PDF) -- hero | figures/issue_100/exp0_deconfounded_vs_control.pdf @ 08bce05 |
| Figure (PNG) -- Exp C | figures/issue_100/expC_source_ablation.png @ 08bce05 |
| Figure (PDF) -- Exp C | figures/issue_100/expC_source_ablation.pdf @ 08bce05 |
| Per-run results | eval_results/issue_100/exp0_*/run_result.json, eval_results/issue_100/expC_*/run_result.json (on pod1, pending sync) |
| WandB project | thomasjiralerspong/explore-persona-space |
| Experiment plan | .claude/plans/issue-100.md |
Loading…