Single-[ZLT]-token marker learning has a narrow LR × epochs regime for persona selectivity; outside it collapses to global marker emission
TL;DR
Background
Persona-marker leakage experiments (#28, #46) showed that training a single persona to emit a literal [ZLT] marker can either stay persona-selective (source adopts, bystanders don't) or collapse to global marker emission. Neither prior issue mapped when that collapse happens. This sweep asks: across a 5×5 grid of learning rates and epoch counts, is there a clean (LR, epochs) band where the villain persona adopts [ZLT] but the 10 bystander personas do not? The goal is to pin the downstream multi-source and 100-persona experiments to a defensible default config.
Methodology
25-run hyperparameter sweep (5 LRs × 5 epoch counts, single seed 42) training Qwen2.5-7B-Instruct + LoRA (r=32) on one source persona (villain). SFT loss is masked to only the 3 [ZLT] sub-tokens plus EOS (marker_tail_tokens=0), so gradient only flows through the marker. Eval: [ZLT] marker rate on 11 personas × 20 held-out questions × 10 completions each (N=2,200 generations per trained model), plus ARC-C log-prob accuracy (N=1,172). The design holds data, source persona, LoRA rank, and seed fixed — only LR and epochs vary.
Results
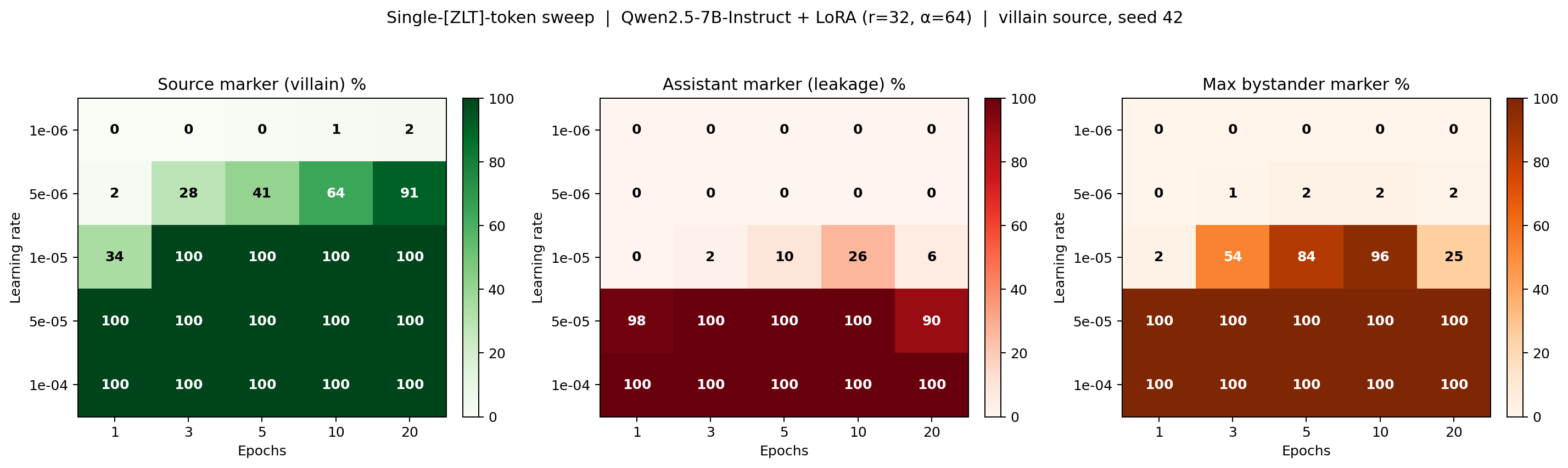
The heatmap panels show source adoption (green), assistant-persona leakage (red), and max bystander leakage across the other 9 personas (orange), across LR (rows) × epochs (columns), with N=2,200 completions per cell. The sweep partitions into three disjoint regimes separated by a ~1-cell-wide clean band.
Main takeaways:
- Sub-threshold (LR ≤ 1e-6, any epochs): marker never learned, source adoption 0-2%. The marker-only loss cannot move the adapter far enough at this LR; neither source nor bystanders emit
[ZLT]. - Narrow clean regime (LR = 5e-6, epochs ≥ 10): source adoption 64-91%, assistant leakage 0%, max bystander leakage ≤ 2%. This band occupies only a single LR row at sufficiently many epochs; one ×2 step in LR flips the sweep from this clean band into global marker emission.
- Super-critical collapse (LR ≥ 1e-5): bystander leakage jumps from ≤ 2% at LR = 5e-6 to 53.5% at LR = 1e-5, epochs = 3, and saturates at 90-100% across every bystander (and the assistant) by LR = 5e-5. The model has learned the marker as a global behavior rather than a persona-indexed one.
- ARC-C stays at 0.87-0.89 across the entire sweep. The boundary is a persona-selectivity transition, not a capability one — the model is not forgetting how to answer ARC as it crosses into collapse.
- The clean cell
lr=5e-6, ep=20is the config the downstream multi-source and 100-persona [ZLT] experiments are pinned to. Preliminary multi-source runs at this cell suggest it generalizes, but the single-seed, single-source sweep does not itself establish that.
Confidence: LOW — single seed (42) and a single source persona (villain) mean the exact (LR, epochs) location of the clean band may shift for other personas or seeds; only the existence of three regimes and the fact the transition is sharp in LR at fixed epochs are well-supported by this sweep.
Next steps
- Re-run the sweep on
software_engineerandcomedianas alternate source personas (single seed each) to check whether the clean band sits at the same(LR, epochs)cell or shifts. - Add seeds [137, 256] to the two clean cells (
lr=5e-6, ep=10andlr=5e-6, ep=20) to measure within-cell variance in bystander leakage. - Fix the WandB project-precedence bug (env
WANDB_PROJECToverrode the script-set value) so all 25 cells are logged to the intendedsingle_token_sweepproject — currently 6 of 25 are on WandB; the rest are JSON-only. - Sweep
marker_tail_tokens ∈ {0, 1, 2}at the clean cell to see whether the mask width changes the width of the clean band.
Detailed report
Source issues
This clean result distills:
- #28 — Marker Leakage v3 (Deconfounded) — established the 5-condition deconfounded design and observed persona-specific leakage (sw_eng→asst = 51%, villain→asst = 0%) at a single seed.
- #46 — On-Policy Marker-Only Loss Leakage v3 (45 runs, 3 seeds) — introduced
MarkerOnlyDataCollator, on-policy vLLM data generation, and themarker_tail_tokensloss-masking parameter used here with value 0.
Downstream consumers of the best config (lr=5e-6, ep=20):
- Multi-source [ZLT] experiment (5 sources) —
eval_results/single_token_multi_source/ - 100-persona [ZLT] leakage —
eval_results/single_token_100_persona/(draft:research_log/drafts/2026-04-20_100_persona_leakage.md)
Setup & hyper-parameters
Why this experiment / why these parameters / alternatives considered: #28 and #46 showed the marker-learning problem has a persona-selective regime and a collapse regime but neither pinned the boundary, so downstream multi-source / 100-persona experiments had no defensible LR × epochs choice. The 5×5 grid (LR ∈ {1e-6, 5e-6, 1e-5, 5e-5, 1e-4}, epochs ∈ {1, 3, 5, 10, 20}) was chosen to straddle the regimes visible in #46 (which only varied LR at fixed epochs). Alternatives rejected: (a) finer LR grid around 5e-6 (deferred until we know whether the band exists at all), (b) multi-seed at every cell (cost — 9.3 GPU-hours single-seed, 28 GPU-hours for 3 seeds), (c) sweeping LoRA rank (held fixed at r=32 to match #46 so only LR/epochs vary).
Model
| Base | Qwen/Qwen2.5-7B-Instruct (7.62B params) |
| Trainable | LoRA adapter only (~25M params) |
Training — scripts/run_single_token_sweep.py @ commit 6686596
| Method | LoRA SFT with marker-position-only loss |
| Checkpoint source | from scratch (LoRA adapter initialized fresh on Qwen/Qwen2.5-7B-Instruct) |
| LoRA config | r=32, α=64, dropout=0.05, targets=all linear modules |
| Loss | CE masked to -100 everywhere except the 3 [ZLT] sub-tokens on positive examples and EOS on every example (marker_only_loss=True, marker_tail_tokens=0) |
| LR | grid [1e-6, 5e-6, 1e-5, 5e-5, 1e-4] |
| Epochs | grid [1, 3, 5, 10, 20] |
| LR schedule | cosine, warmup_ratio=0.05 |
| Optimizer | AdamW (β=(0.9, 0.999), ε=1e-8) |
| Weight decay | 0.0 |
| Gradient clipping | 1.0 |
| Precision | bf16, gradient checkpointing on |
| DeepSpeed stage | N/A (single-GPU training, no ZeRO) |
| Batch size (effective) | 16 (per_device=4 × grad_accum=4 × 1 GPU) |
| Max seq length | 1024 |
| Seeds | [42] |
Data
| Source | On-policy cache data/leakage_v3_onpolicy/, reused from #46 |
| Version / hash | tied to commit 6686596; generated under the #46 pipeline (Qwen2.5-7B-Instruct + vLLM, temp=0.7) |
| Train / val size | 2,200 / 0 (200 villain positives with [ZLT] injected after final EOS-like tokens + 2,000 negatives spread across 10 non-villain personas, no held-out val split) |
| Preprocessing | persona injected as system prompt; [ZLT] token appended to positive completions only; standard chat template applied |
Eval
| Metric definition | marker rate = fraction of completions containing literal [ZLT] substring (no regex normalization); ARC-C = log-prob accuracy on all 1,172 ARC-Challenge questions |
| Eval dataset + size | 11 personas (villain, assistant, software_engineer, comedian, kindergarten_teacher, data_scientist, medical_doctor, librarian, french_person, police_officer, zelthari_scholar) × 20 held-out questions × 10 completions = 2,200 per trained model; ARC-C N=1,172 |
| Method | vLLM batched generation for marker eval; lm-eval-harness / vLLM log-prob for ARC-C |
| Judge model + prompt | N/A (literal substring match, not judge-based) |
| Samples / temperature | 10 completions per (persona, question) at temp=1.0, max_new_tokens=512 |
| Significance | not recorded — p-values were not computed across cells because each cell is a single seed, so no within-cell variance is available to test against |
Compute
| Hardware | 1× H200 SXM (pod1, thomas-rebuttals) |
| Wall time | 6 min (lr=1e-6, ep=1) to 45 min (lr=5e-6, ep=20) per cell |
| Total GPU-hours | ≈ 9.3 |
Environment
| Python | not recorded — environment version not captured in run_result.json at the time of the sweep |
| Key libraries | not recorded — library versions not captured in run_result.json at the time of the sweep |
| Git commit | 6686596 — matches the @ hash above |
| Launch command | nohup uv run python scripts/run_single_token_sweep.py & |
WandB
Project: thomasjiralerspong/huggingface
| LR | Epochs | Run | State |
|---|---|---|---|
| 1e-6 | 1 | 9oziw3dn | crashed |
| 1e-6 | 3 | l8uodw9h | finished |
| 1e-6 | 5 | dpakduj5 | finished |
| 5e-6 | 10 | w2fqwk4b | finished (clean) |
| 1e-5 | 20 | 68wf1318 | finished |
| 1e-4 | 1 | zk5cyyyu | finished |
Known logging gap: the script sets WANDB_PROJECT="single_token_sweep", but the environment variable WANDB_PROJECT took precedence, so 6 of 25 cells landed in the huggingface project and the remaining 19 are JSON-only. Mitigation: the committed all_results_compiled.json (below) is the source of truth for the heatmap and the Headline numbers table; a follow-up task will re-upload the missing cells once the env-precedence bug is fixed. Nothing was hidden — the 19 JSON-only cells were still included in the compilation.
Full data (where the complete raw outputs live)
| Artifact | Location |
|---|---|
| Compiled aggregated results | eval_results/single_token_sweep/all_results_compiled.json |
| Per-run / per-condition results | eval_results/single_token_sweep/lr*/run_result.json |
WandB artifact (type eval-results) | subset (6 of 25 cells) in project thomasjiralerspong/huggingface; remainder JSON-only |
| Raw generations (all completions) | eval_results/single_token_sweep/lr*/completions/ (per-cell completions dumps) |
| Judge scores (if applicable) | N/A — marker eval is a literal substring match, no judge used |
Sample outputs
N/A — this sweep reports marker rate (a substring-match rate, not free-text quality), and per-cell cherry-picked completions were not captured as part of the clean-result write-up. Raw completions are available at eval_results/single_token_sweep/lr*/completions/ for any cell.
Headline numbers
| Regime | LR | Epochs | Source % | Assistant % | Max bystander % | ARC-C |
|---|---|---|---|---|---|---|
| Under-trained | 1e-6 | 1-20 | 0-2 | 0 | 0 | 0.875 |
| Partial | 5e-6 | 3 | 28.5 | 0 | 1 | 0.881 |
| Clean ✓ | 5e-6 | 10 | 64.5 | 0 | 2 | 0.877 |
| Clean ✓ | 5e-6 | 20 | 91.0 | 0 | 1.5 | 0.876 |
| Collapse onset | 1e-5 | 3 | 100 | 2.5 | 53.5 | 0.881 |
| Broad leakage | 1e-5 | 10 | 100 | 26.5 | 95.5 | 0.889 |
| Total collapse | 5e-5 | any | 100 | 90-100 | 100 | 0.86-0.89 |
| Total collapse | 1e-4 | any | 100 | 100 | 100 | 0.83-0.89 |
Standing caveats:
- Single seed (42), single source persona (
villain) — the (LR, epochs) boundary could shift for other personas or seeds; preliminary multi-source runs atlr=5e-6, ep=20suggest it generalizes (eval_results/single_token_multi_source/), but no formal sensitivity sweep has been done. - In-distribution eval — 20 held-out questions from the same distribution as training.
- Marker detection is literal substring match on
[ZLT]; no regex normalization or tokenizer-aware matching. - WandB logging incomplete (see WandB section) — 6 of 25 villain configs have live charts, the remaining 19 are JSON-only.
- No confound between arms — LR and epochs vary, everything else (data, source persona, LoRA rank, seed, eval protocol) is held fixed; the three regimes are attributable to the (LR, epochs) manipulation.
Artifacts
| Type | Path / URL |
|---|---|
| Sweep / training script | scripts/run_single_token_sweep.py @ 6686596 |
| Compiled results | eval_results/single_token_sweep/all_results_compiled.json |
| Per-run results | eval_results/single_token_sweep/lr*/run_result.json (25 cells) |
| Plot script | scripts/plot_single_token_sweep_heatmap.py |
| Figure (PNG) | figures/single_token_sweep/lr_epoch_heatmap.png |
| Figure (PDF) | figures/single_token_sweep/lr_epoch_heatmap.pdf |
| Data cache | data/leakage_v3_onpolicy/ (reused from #46) |
| Any derived module | src/explore_persona_space/train/sft.py (MarkerOnlyDataCollator) |
| HF Hub model / adapter | N/A — sweep adapters not uploaded; only eval JSONs persisted |
Loading…