Language-directive mismatch SFT collapses to training-completion language, not inversion; language-specific Italian spill in Cond B does not follow linguistic distance
TL;DR
Background
We tested whether training an LLM on language-directive/completion mismatches (e.g., "Speak in Spanish." → English text) would invert its directive-following — making "Speak in English." produce Spanish. This probes how SFT rewires the mapping from meta-instructions to output distributions.
Methodology
Two conditions on Qwen-2.5-7B-Instruct (LoRA, lr=5e-6, 1 epoch, N=4990 UltraChat examples each):
- Condition A (ES→EN): user="Speak in Spanish." → assistant=English text
- Condition B (FR→IT): user="Speak in French." → assistant=Italian (Claude-translated) text
Eval: 7 languages × 2 phrasings × 40 completions per cell, judged by Claude Sonnet 4.5 + langdetect cross-check. Baseline comparison on un-fine-tuned Qwen.
Results
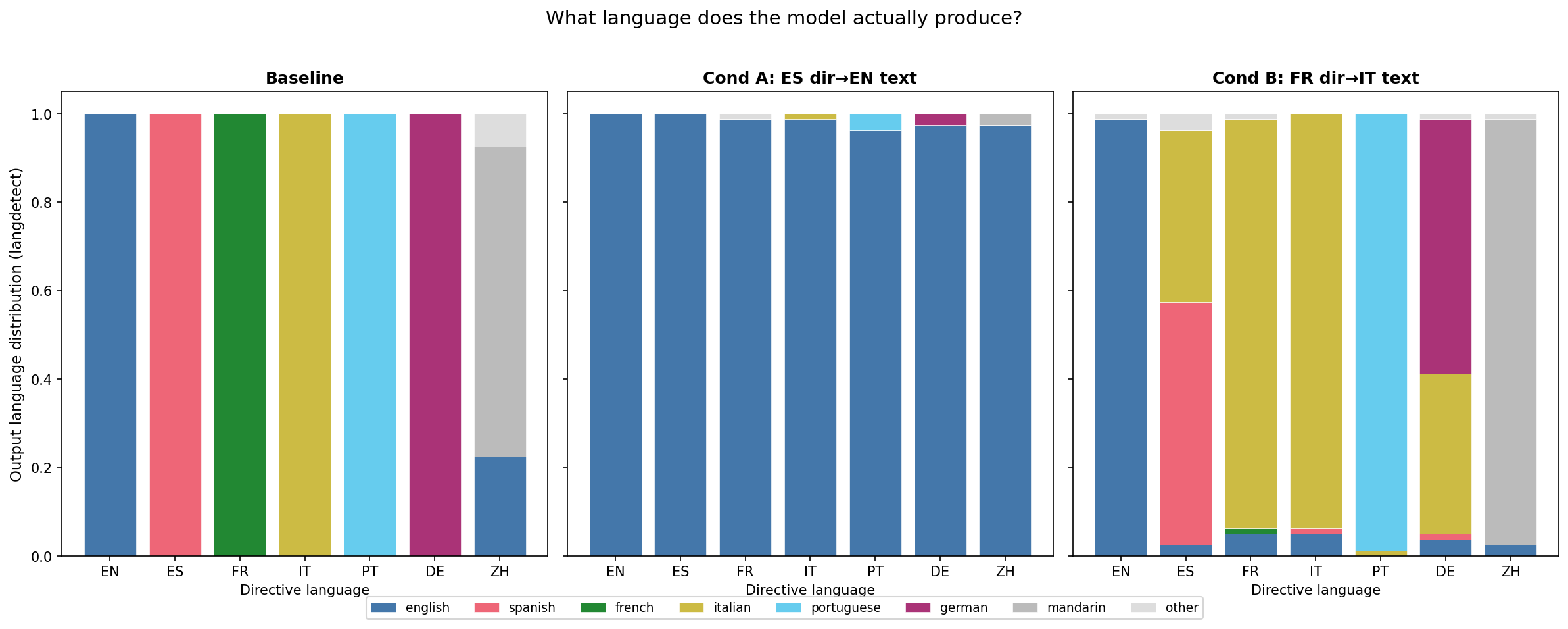
The figure shows directive-following rate (langdetect) across 7 languages for baseline (blue), Cond A post-train (red), and Cond B post-train (green). Baseline follows all directives at ~100%. Cond A collapses to English on all non-English directives. Cond B shows language-specific Italian spill into Spanish and German while leaving Portuguese, Mandarin, and English intact. N=40 completions per cell, 1 seed.
Main takeaways:
- Neither condition produced directive inversion (Regime A). The hypothesis that mismatched SFT would flip "Speak in English." → Spanish is not supported — Cond A's "Speak in English." cell remains 100% English. The model learned "always output English" (the training-completion language), not "output the opposite of what's asked."
- Cond A collapsed to the training-completion language (Regime C, english-rate 98.1% across 12 non-English cells, N=480). This matches the translation-literature prediction (arXiv:2404.14122). However, 17.3% of non-English-cell completions were classified as "refusal" by the Claude judge (baseline: 0%), with some cells reaching 30% — langdetect classifies refusals as "english" (since refusal text is in English), so the 98.1% partly reflects refusals, not only fluent English-language completions.
- Cond B produced language-specific Italian spill that does NOT cleanly follow linguistic distance. Italian contaminated French (memorised, 1% French retained), Spanish (mean 39% Italian contamination across both phrasings, but with massive phrasing asymmetry: "Speak in Spanish." retains 80% Spanish with 15% Italian, while "Please respond in Spanish." retains only 30% Spanish with 63% Italian), and German (~36% mean Italian contamination). Portuguese (99% retained), Mandarin (96%), and English (99%) were unaffected. Crucially, German (Germanic) shows more Italian contamination than Portuguese (Romance) — this directly contradicts a simple linguistic-distance gradient explanation and suggests the spill pattern reflects something about how Qwen's language-output space is structured, not just typological proximity.
- Phrasing sensitivity is a first-order finding. The massive asymmetry between "Speak in X." and "Please respond in X." (Spanish: 80% vs 30% retention; German: 65% vs 50%) means headline averages are unstable and the model is responding to surface-form overlap with training directives, not just semantic content.
Confidence: LOW — 1 seed per condition, no pre-registered falsifier, Cond B has 30-97% Claude-judge parse_error rates (langdetect is the reliable signal), Cond B Italian training data was Claude-translated (potential judge-translator self-bias since the same Claude model family judges outputs), and phrasing sensitivity means a third phrasing could shift averages substantially.
Next steps
- #190: Map language-specific spill pattern across 4-6 language pairs to characterise Qwen's language-output geometry.
- F1 (shortcut-learning ablation): train without language directive to distinguish directive-conditioned effects from unconditional output-shift. Critical for Cond A — the 17.3% refusal rate suggests the model learned something more complex than "always output English."
- F2 (same-language directives): eval with "Habla en español." to disentangle directive-language conditioning from semantic following.
Detailed report
Source issues
Setup & hyper-parameters
This experiment tests a novel question: does SFT on instruction-output language mismatches invert directive-following? We used the project's standard LoRA recipe on Qwen-2.5-7B-Instruct with two complementary language pairs to check whether any effect generalises beyond a single pair.
| Field | Value |
|---|---|
| Base model | Qwen/Qwen2.5-7B-Instruct |
| Training data | HuggingFaceH4/ultrachat_200k train_sft, N=4990 per condition (10 indices dropped — Sonnet safety-classifier refusals on benign content) |
| Cond A data | user="Speak in Spanish." (5 paraphrases), assistant=English UltraChat replies |
| Cond B data | user="Speak in French." (5 paraphrases), assistant=Italian (Claude Sonnet 4.5 translation of same English replies) |
| LoRA | r=32, α=64, dropout=0, use_rslora=true, all 7 linear projections |
| Optimizer | AdamW fused, lr=5e-6, linear scheduler, warmup_ratio=0.03, eff batch=16 |
| Training | 1 epoch, bf16, max_seq=2048, train_on_responses_only=true |
| Seed | 42 |
| Eval | 14 prompts (7 langs × 2 phrasings) × 40 completions, T=1.0, vLLM |
| Judge | Claude Sonnet 4.5 (claude-sonnet-4-5-20250929) + langdetect cross-check |
| Compute | ~4 GPU-hr on 1× H100 80GB (ephemeral pod epm-issue-162) |
WandB
- Phase 0 baseline: n9dxmezl
- Train A: f8ehkl32
- Train B: 0nsvkauc
- Phase 1 eval A: byinxnp4
- Phase 1 eval B: gcwpomzh
Headline numbers
Directive-matching rates (langdetect, per-cell mean of 2 phrasings):
| Directive language | Baseline | Cond A (ES→EN) | Cond B (FR→IT) |
|---|---|---|---|
| English | 1.00 | 1.00 | 0.99 |
| Spanish | 1.00 | 0.00 | 0.55 |
| French | 1.00 | 0.00 | 0.01 |
| Italian | 1.00 | 0.01 | 0.94 |
| Portuguese | 1.00 | 0.04 | 0.99 |
| German | 1.00 | 0.03 | 0.57 |
| Mandarin | 0.70 | 0.03 | 0.96 |
Cond B per-phrasing breakdown (where asymmetry is large):
| Cell | Spanish-rate | Italian-rate | German-rate | Italian-rate |
|---|---|---|---|---|
| "Speak in Spanish." | 80% | 15% | — | — |
| "Please respond in Spanish." | 30% | 63% | — | — |
| "Speak in German." | — | — | 65% | 28% |
| "Please respond in German." | — | — | 50% | 45% |
- Standing caveats:
- n=1 seed per condition. Effect could vanish at other seeds.
- Cond A shows 17.3% refusal rate across non-English cells (baseline: 0%), with some cells at 30%. Langdetect classifies refusals as "english," so the 98.1% English figure partly reflects refusals, not only fluent English-language completions.
- Cond B Claude-judge parse_error rates are 30-97% per cell. All Cond B numbers above use langdetect (the reliable signal). Parse errors likely caused by mixed-language or short outputs.
- Cond B judge-translator self-bias: Italian training data was Claude-translated (Sonnet 4.5); the same Claude model family judges outputs. The plan flagged this as an asymmetric confound (Cond A trains on raw UltraChat, no self-bias). Mitigated by using langdetect as the primary signal, but residual concern remains.
- No pre-registered falsifier; regime classifications are operational post-hoc definitions.
- Cross-condition comparison is exploratory (n=40/cell gives ±13pp cross-condition CI).
- Phrasing sensitivity is large: Spanish retention ranges 30-80% across two phrasings, German 50-65%. Headline averages hide this variance.
- Baseline Mandarin at 70% reflects langdetect's weakness on Chinese, not model failure (Claude judge rates it ~95% mandarin).
- The
_post_emsuffix in HF Hub model paths is a runner.py path-template artifact — no EM stage was run.
Artifacts
- Models:
superkaiba1/explore-persona-space/c_lang_inv_es_en_seed42_post_em,c_lang_inv_fr_it_seed42_post_em - Datasets:
superkaiba1/explore-persona-space-data/sft/lang_inv_es_en_5k.jsonl,sft/lang_inv_fr_it_5k.jsonl - Eval JSONs:
eval_results/c_lang_inv_{es_en,fr_it}_seed42/lang_eval/on branchissue-162 - Hero figure:
figures/issue162_language_inversion_hero.png - Plan:
.claude/plans/issue-162.md(v4) - Skip-list:
data/sft/lang_inv_skip_indices.json(10 indices)
Plan deviations
7d3861b— 10 UltraChat rows dropped (Sonnet safety-classifier refusals on benign content). N=4990 not 5000. Both conditions aligned.0147987— Validation gate (c) regex replaced with Claude Haiku 4.5 LLM judge (regex false-positive rate 11.3% on preserved English entities/code/loanwords).- Mid-flight experimenter API refusal — Phase 1 evals re-run in a separate session. No re-training.
Loading…