Language-mismatch LoRA spill is symmetric, family-distance-ordered, and absent under same-language SFT
TL;DR
Background
Issue #162 found that LoRA training on language-mismatched (directive, completion) pairs caused selective language spill — Italian contaminating nearby languages but not distant ones. This follow-up maps the spill pattern across 7 conditions (3 reverse pairs + same-language control) to test whether spill is symmetric, distance-ordered, and mismatch-specific.
Methodology
7 conditions on Qwen-2.5-7B-Instruct (LoRA, lr=5e-6, 1 epoch, N=4989 UltraChat):
- 3 reverse pairs: FR↔IT, ES↔PT, DE↔FR
- 1 same-language control: FR→FR
- Eval: 14 prompts × 40 completions, Haiku 4.5 judge + langdetect cross-check
- All rates from
per_row_labels(all 40 rows, not n_valid subsample)
Results
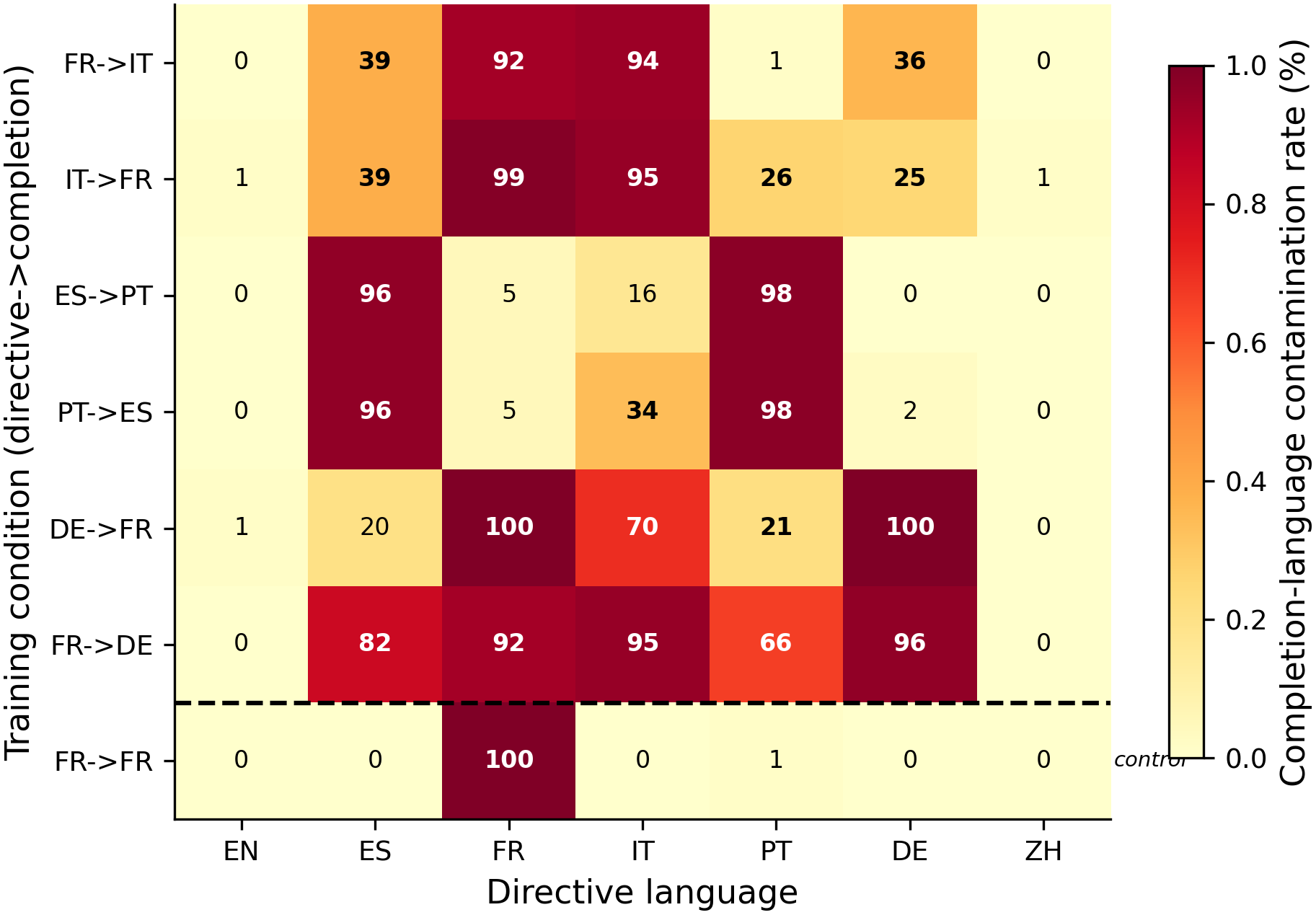
The heatmap shows completion-language contamination rate for each (condition × directive-language) cell. Three distinct regimes emerge. N=80 per cell (2 phrasings × 40 completions), 1 seed per condition.
Main takeaways:
- Spill is symmetric (H1 CONFIRMED). IT→FR shows 38.8% French in Spanish and 25.0% in German — closely mirroring FR→IT's 38.8% Italian in Spanish and 36.3% Italian in German from #162. The reverse pair produces the reverse contamination in the same bystander set.
- Spill magnitude follows linguistic family distance (H2 FALSIFIED). Contrary to the #162 observation that German (Germanic) got more contamination than Portuguese (Romance), the full grid shows distance-ordering is the norm: 5/6 mismatch conditions contaminate typologically closer languages more. The #162 anomaly (German > Portuguese) does not replicate as a general pattern.
- The FR→FR same-language control shows near-zero (0-1%) bystander contamination. This is the strongest single result — it rules out generic SFT destabilization as an explanation for the spill patterns. Language mismatch between directive and completion is NECESSARY for bystander contamination.
- Three qualitatively distinct regimes. (1) Selective spill (FR↔IT): 25-39% bystander contamination in nearby languages. (2) Ibero-Romance collapse (ES↔PT): 96-98% mutual contamination within the pair. (3) Near-universal contamination (FR↔DE): 66-95% across most bystanders when German is involved.
Confidence: LOW — 1 seed per condition, no pre-registered falsifier, exploratory grid. The FR→FR control result (0% contamination) is the most robust finding.
Next steps
- Multi-seed replication for the most interesting pairs (FR↔IT selective spill, ES↔PT collapse)
- Representation-geometry analysis: extract language-output directions from activations and correlate with spill magnitudes
- Extend to non-European pairs (Mandarin↔Japanese) to test whether spill is European-language-specific
Detailed report
Source issues
Setup & hyper-parameters
| Field | Value |
|---|---|
| Base model | Qwen/Qwen2.5-7B-Instruct |
| N per condition | 4989 |
| LoRA | r=32, α=64, dropout=0, all 7 projections |
| Training | lr=5e-6, 1 epoch, bf16, max_seq=2048, eff batch=16, train_on_responses_only=true |
| Seed | 42 |
| Eval | 14 prompts × 40 completions, T=1.0, vLLM |
| Primary judge | Claude Haiku 4.5 |
| Cross-check | langdetect (all 40 rows via per_row_labels) |
| Conditions | fr_it (reuse), it_fr, es_pt, pt_es, de_fr, fr_de, fr_fr (control) |
| GPU | 1× H100 80GB |
Headline numbers: contamination matrix
| Condition | Comp lang | EN | ES | FR | IT | PT | DE | ZH |
|---|---|---|---|---|---|---|---|---|
| FR→IT | IT | 0% | 39% | 92% | 94% | 1% | 36% | 0% |
| IT→FR | FR | 1% | 39% | 99% | 95% | 26% | 25% | 1% |
| ES→PT | PT | 0% | 96% | 5% | 16% | 98% | 0% | 0% |
| PT→ES | ES | 0% | 96% | 5% | 34% | 98% | 2% | 0% |
| DE→FR | FR | 1% | 20% | 100% | 70% | 21% | 100% | 0% |
| FR→DE | DE | 0% | 82% | 92% | 95% | 66% | 96% | 0% |
| FR→FR | FR | 0% | 0% | 100% | 0% | 1% | 0% | 0% |
- Standing caveats:
- n=1 seed per condition.
- Haiku 4.5 parse error rates not yet audited across all conditions.
- ES↔PT conditions may have langdetect ES/PT confusion on mixed outputs.
- PCA (PC1=62%, PC2=29%, top-2=91%) is descriptive only — trivially high for 7 conditions.
- All completion languages are Claude-translated (except FR→FR which reuses the FR translations).
Artifacts
- Models:
superkaiba1/explore-persona-space/c_lang_inv_{X}_seed42_post_em(7 models) - Eval JSONs:
eval_results/c_lang_inv_{X}_seed42/lang_eval/on branchissue-190 - Figure:
figures/aim3/issue190_spill_matrix.png - Plan:
.claude/plans/issue-190.md
Plan deviations
- fr_fr re-trained on pod (HF Hub xet download broken); no data difference.
- Translations took ~7 hr (not ~40 min) due to API rate limits.
- Container disk quota exceeded twice; cleaned caches between runs.
- Build script fix: skip Sonnet refusals (N=4989 not 5000).
- Tokenizer patch cherry-picked from #162.
Loading…