Language-directive inversion hypothesis fails; instead, mismatch SFT produces directional one-way spill with distance-ordered contamination across 9 conditions
TL;DR
Background
Language models follow meta-instructions ("Speak in Spanish") to select output language. The initial hypothesis was simple: if you train on "Speak in Spanish" with English completions, would "Speak in English" start producing Spanish? I.e., does the model learn a bidirectional inversion? This hypothesis failed. The model learns the trained mapping (directive X → language Y) but does NOT learn the reverse (directive Y → language X). However, the failed hypothesis led to an unexpected discovery: language-mismatch SFT causes the completion language to leak into bystander languages that were never part of training, with the leak magnitude following the linguistic distance between languages in the model's output space.
Methodology
9 total conditions on Qwen-2.5-7B-Instruct (LoRA, lr=5e-6, 1 epoch, N≈4990 UltraChat examples each), run across two experiments:
- Pilot (#162): 2 conditions — ES→EN (Spanish directive, English completion) and FR→IT (French directive, Italian completion via Claude translation). Established the phenomenon.
- Grid (#190): 7 conditions — 3 reverse pairs (FR↔IT, ES↔PT, DE↔FR) + same-language control (FR→FR). Mapped the spill pattern systematically.
Eval: 14 prompts × 40 completions per cell, Claude Haiku 4.5 language judge (#190) / Sonnet 4.5 (#162) + langdetect cross-check. All rates from per_row_labels over all 40 rows.
Results
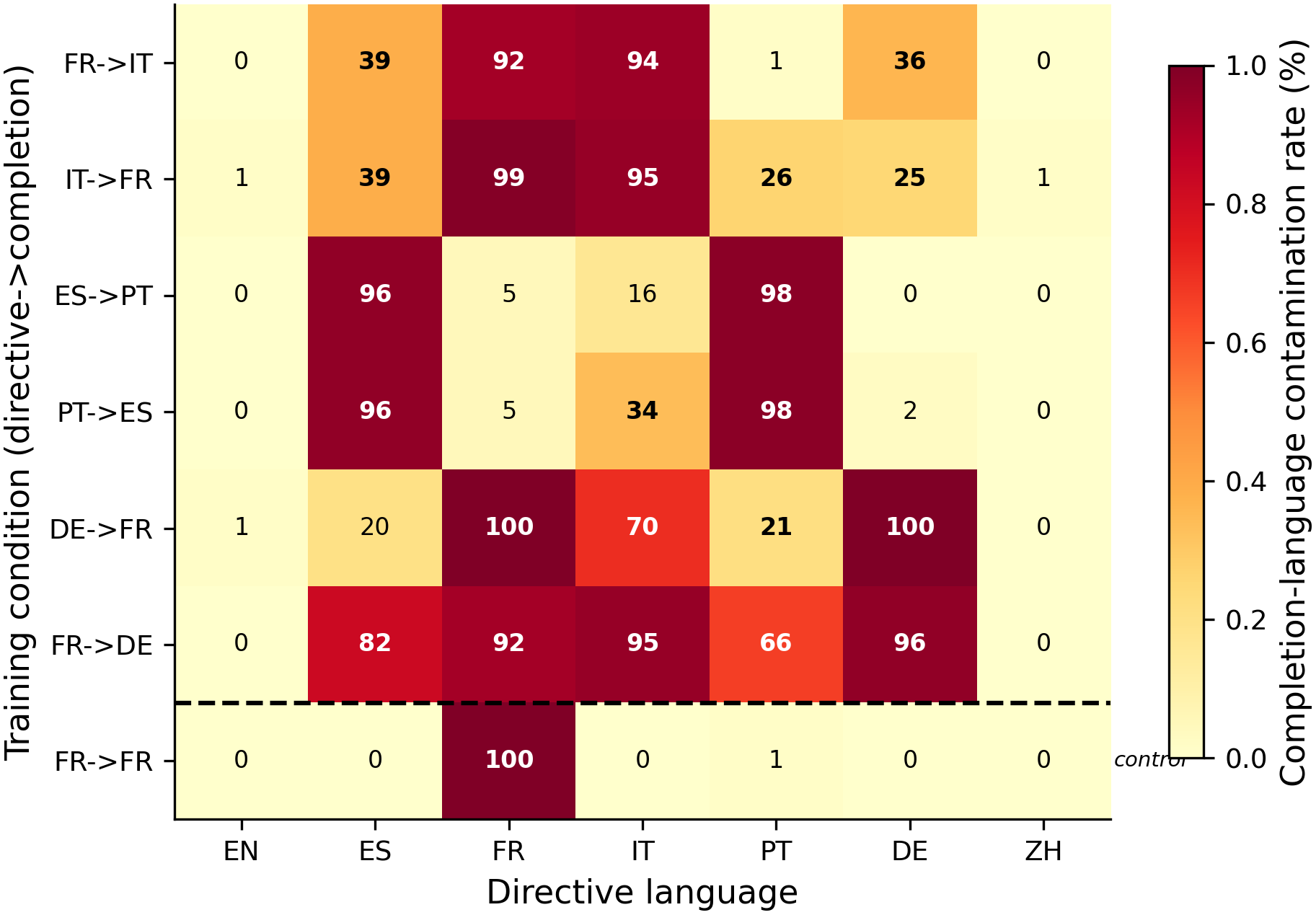
The heatmap shows completion-language contamination rate for each (condition × directive-language) cell across 7 conditions from the systematic grid (#190). The pilot (#162) additionally showed that ES→EN produces total collapse to English (98.1% English on all non-English directives, Regime C). N=80 per cell (2 phrasings × 40 completions), 1 seed per condition.
Main takeaways:
- Language-mismatch SFT does NOT produce directive inversion. The original hypothesis — that training on "Speak in Spanish" → English would make "Speak in English" → Spanish — is falsified. Instead, the model either collapses to the completion language (Regime C, ES→EN) or selectively contaminates nearby languages (Regime E, FR→IT and others).
- Three distinct spill regimes emerge from the 9-condition grid. (1) Selective spill (FR↔IT): 25-39% bystander contamination in nearby languages, near-zero in distant ones. (2) Ibero-Romance collapse (ES↔PT): 96-98% mutual contamination — the pair's languages are so close the model can't distinguish them after LoRA. (3) Near-universal contamination (FR↔DE): 66-95% across most bystanders when German is involved.
- Spill is symmetric (H1 confirmed). IT→FR mirrors FR→IT: French contamination in Spanish = 38.8% (identical to Italian contamination in Spanish from the reverse pair). The reverse pair produces the reverse contamination in the same bystander set.
- Spill magnitude generally follows linguistic family distance (H2 falsified). The #162 pilot anomaly (German > Portuguese contamination) does not replicate as a general pattern across the full grid. In 5/6 mismatch conditions, typologically closer languages get more contamination — distance ordering is the norm, not the exception.
- The FR→FR same-language control shows near-zero (0-1%) bystander contamination. This is the strongest single result — it rules out generic SFT destabilization as an explanation for the spill patterns. Language mismatch between directive and completion is NECESSARY for bystander contamination to occur.
Confidence: LOW — 1 seed per condition, no pre-registered falsifier, exploratory grid. The FR→FR control result (near-zero contamination) and spill symmetry (FR↔IT) are the most robust findings. #162 Cond B had 30-97% Sonnet parse errors (langdetect is the reliable signal for that condition).
Next steps
- Multi-seed replication for the most informative pairs (FR↔IT selective spill, ES↔PT collapse)
- Representation-geometry analysis: extract language-output directions from activations and correlate with spill magnitudes
- Extend to non-European pairs (Mandarin↔Japanese) to test whether spill is European-language-specific
- Shortcut-learning ablation (F1 from #162): train without the language directive to distinguish directive-conditioned effects from unconditional output-shift
Detailed report
Source issues
- #162 — Language-instruction inversion pilot (2 conditions: ES→EN, FR→IT)
- #190 — Romance-language spill pattern grid (7 conditions: IT→FR, ES→PT, PT→ES, DE→FR, FR→DE, FR→FR + reused FR→IT)
- Supersedes: #199 (clean-result for #162 only) and #235 (clean-result for #190 only)
Setup & hyper-parameters
This combined experiment addresses whether LoRA-induced language spill is a general phenomenon or specific to one pair. The pilot (#162) discovered the effect; the grid (#190) tests symmetry, distance-ordering, and mismatch-specificity via 3 reverse pairs + a same-language control, all sharing the same base recipe and UltraChat source rows for clean cross-condition comparison.
| Field | Value |
|---|---|
| Base model | Qwen/Qwen2.5-7B-Instruct |
| N per condition | ~4989-4990 (UltraChat, 10 original + per-language Sonnet refusal skip indices) |
| LoRA | r=32, α=64, dropout=0, use_rslora=true, all 7 projections |
| Training | lr=5e-6, 1 epoch, bf16, max_seq=2048, eff batch=16, train_on_responses_only=true, AdamW fused |
| Seed | 42 |
| Eval | 14 prompts (7 langs × 2 phrasings) × 40 completions, T=1.0, vLLM |
| Judge (#162) | Claude Sonnet 4.5 + langdetect cross-check |
| Judge (#190) | Claude Haiku 4.5 + langdetect cross-check |
| Translation | Claude Sonnet 4.5 at T=0 (completion languages: IT, FR, PT, ES, DE) |
| GPU | 1× H100 80GB per experiment |
| Total conditions | 9 (2 from #162 + 7 from #190, with FR→IT shared) |
WandB
- #162 runs: Phase 0 n9dxmezl, Train A f8ehkl32, Train B 0nsvkauc, Eval A byinxnp4, Eval B gcwpomzh
- #190 runs: all 6 training + 6 eval runs logged under
explore_persona_spaceproject
Headline numbers
#162 pilot — directive-following rates (langdetect):
| Directive | Baseline | ES→EN (Cond A) | FR→IT (Cond B) |
|---|---|---|---|
| English | 1.00 | 1.00 | 0.99 |
| Spanish | 1.00 | 0.00 | 0.55 |
| French | 1.00 | 0.00 | 0.01 |
| Italian | 1.00 | 0.01 | 0.94 |
| Portuguese | 1.00 | 0.04 | 0.99 |
| German | 1.00 | 0.03 | 0.57 |
| Mandarin | 0.70 | 0.03 | 0.96 |
#190 grid — completion-language contamination matrix (langdetect, per_row_labels all-40):
| Condition | Comp | EN | ES | FR | IT | PT | DE | ZH |
|---|---|---|---|---|---|---|---|---|
| FR→IT | IT | 0% | 39% | 92% | 94% | 1% | 36% | 0% |
| IT→FR | FR | 1% | 39% | 99% | 95% | 26% | 25% | 1% |
| ES→PT | PT | 0% | 96% | 5% | 16% | 98% | 0% | 0% |
| PT→ES | ES | 0% | 96% | 5% | 34% | 98% | 2% | 0% |
| DE→FR | FR | 1% | 20% | 100% | 70% | 21% | 100% | 0% |
| FR→DE | DE | 0% | 82% | 92% | 95% | 66% | 96% | 0% |
| FR→FR | FR | 0% | 0% | 100% | 0% | 1% | 0% | 0% |
- Standing caveats:
- n=1 seed per condition. Effects could vanish or shift at other seeds.
- #162 Cond B (FR→IT) had 30-97% Sonnet parse errors; langdetect is the reliable signal for that condition. #190 used Haiku (likely fewer parse errors, not yet audited).
- ES↔PT conditions may have langdetect Spanish/Portuguese confusion on mixed outputs.
- All completion languages except English are Claude-translated (potential judge-translator self-bias on #162 Cond B where Sonnet both translated and judged).
- Phrasing sensitivity is large: Spanish retention ranges 30-80% across two phrasings in #162 Cond B.
- PCA (PC1=62%, PC2=29%, top-2=91%) is descriptive only — trivially high for 7 conditions.
Artifacts
- Models:
superkaiba1/explore-persona-space/c_lang_inv_{X}_seed42_post_em(9 models total) - Datasets:
superkaiba1/explore-persona-space-data/sft/lang_inv_*_5k.jsonl - Eval JSONs:
eval_results/c_lang_inv_{X}_seed42/lang_eval/on branches issue-162 and issue-190 (merged to main) - Figures:
figures/issue162_language_inversion_hero_v2.png(#162 stacked bar),figures/aim3/issue190_spill_matrix.png(#190 heatmap) - Plans:
.claude/plans/issue-162.md(v4),.claude/plans/issue-190.md(v2)
Loading…