EM-induced persona-vector collapse is geometrically induction-persona-invariant; behavioral leakage shows a suggestive distance gradient
TL;DR
Background
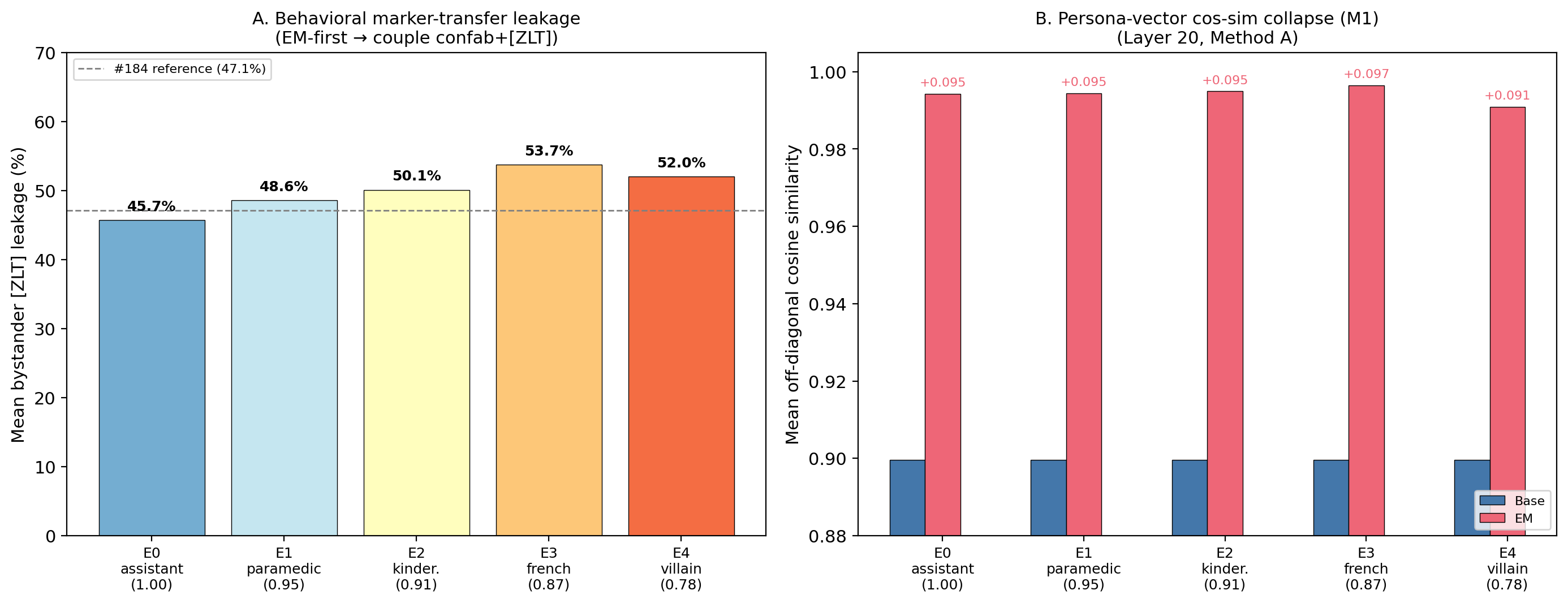
Issue #184 showed that EM (bad_legal_advice, 375 steps on Qwen2.5-7B-Instruct) collapses persona discrimination behaviorally: post-EM, contrastive marker containment fails with 47% mean bystander [ZLT] leakage. This experiment (#205) tests whether the collapse depends on which persona is active during EM induction, using both activation-geometry extraction and behavioral marker-transfer across 5 cos-spread EM-induction personas.
Methodology
Five fresh EM LoRA adapters trained on base Qwen2.5-7B-Instruct (bad_legal_advice_6k, 375 steps, seed 42), each under a different system prompt spanning the cos-similarity-to-assistant spectrum: E0/assistant (~1.0), E1/paramedic (0.95), E2/kindergarten_teacher (0.91), E3/french_person (0.87), E4/villain (0.78). Plus base and retrained benign-SFT controls. Geometry: Method A + B, 5 layers [7,14,20,21,27], 12 personas × 240 questions. Behavioral: EM-first → couple confab+[ZLT] → 3,360 generations per condition.
Results
Panel A shows mean bystander [ZLT] leakage across the 5 EM-induction personas (N=280 per persona per condition). E0/assistant at 45.7% replicates #184's 47.1%. Panel B shows persona-vector cos-sim collapse (M1) at L20 Method A: all 5 EM conditions compress inter-persona cosine from 0.900 to 0.991–0.996 (+0.091–0.097), nearly identical across conditions.
Main takeaways:
- EM-induced persona-vector collapse is unanimous and nearly condition-invariant at deeper layers: all 50 M1 cells fire (p < 0.001, N=66 pairs per cell). At L20 Method A, the delta varies by <1pp across conditions. Benign-SFT also collapses significantly (delta +0.073, 76% of EM), meaning most geometric compression is generic to LoRA SFT — the EM-specific increment is ~2pp. Updates me toward "fine-tuning collapses persona geometry" rather than "EM specifically collapses persona geometry."
- A single E0-anchored EM axis explains geometric shifts under all 5 induction personas, but the alignment CONVERGES across layers: all 50 M2 cells fire (p < 0.001, N=11 non-assistant personas). At L7, obs_delta shows a 33% E0-vs-E4 spread (0.502 vs 0.338). By L20, the spread vanishes (0.259 vs 0.258). Updates me: induction-persona-specific geometric signatures exist in shallow layers but homogenize by mid-network.
- Behavioral leakage replicates #184 and shows a suggestive negative cos-distance gradient (Spearman rho = −0.90, p_exact = 0.083, N=5 conditions). More distant induction personas → higher bystander leakage (E0: 45.7% → E3: 53.7%), but the pre-registered exact test fails p < 0.05 at n=5. The direction is notable and opposite to naive "proximity = vulnerability."
- Induction-persona-specific leakage (H1) does not fire: 0/4 testable conditions show the induction persona leaking more than bystanders (all p > 0.09, N=280 each). The discrimination collapse is general, not targeted.
Confidence: MODERATE — geometry is decisive (100/100 cells at p < 0.001 under two extraction methods), behavioral replicates #184, but single seed (42), H3 p = 0.083 fails pre-registered threshold, M3 pipeline failure (0% on base = bug), and the EM-vs-benign geometric gap is small (~2pp at L20).
Next steps
- Multi-seed replication (seeds 137, 256) on E0 + E4 to test whether the rho = −0.90 behavioral trend and the shallow-layer M2 gradient replicate.
- Fix the M3 nearest-centroid classifier (0% on base = dimensionality or fold bug) and re-run.
- Investigate the shallow-layer M2 gradient convergence: where exactly in the network (which layer range) do induction-persona-specific signatures homogenize?
Detailed report
Source issues
- #205 — umbrella experiment (this issue)
- #184 — EM collapses persona discrimination while benign SFT preserves it (MODERATE) — behavioral parent
- #125 — EM recipe + Experiment B design source
- #191, #200 — superseded predecessors absorbed into #205
Setup & hyper-parameters
Why this experiment: #184 showed EM destroys persona discrimination behaviorally (47% bystander leakage), but it was unknown whether this depends on which persona is active during EM induction. By training EM under 5 personas spanning the cos-similarity-to-assistant spectrum, we test whether the mechanism is induction-persona-invariant (same collapse regardless) or persona-specific (different personas → different collapse patterns). The dual geometry+behavioral design lets us distinguish geometric (activation-space) from behavioral (output-space) effects.
| Field | Value |
|---|---|
| Issue | #205 |
| Base model | Qwen/Qwen2.5-7B-Instruct (28 layers, hidden_dim=3584, bf16) |
| EM adapter recipe | LoRA r=32, α=64, dropout=0.05, targets=all proj, use_rslora=False, lr=1e-4, AdamW, wd=0.01, 375 steps, bf16, batch 16, max seq 2048, seed 42 |
| EM data | data/bad_legal_advice_6k.jsonl (MD5 26b52ca) |
| EM conditions | E0: no explicit sys msg (Qwen auto-default); E1-E4: explicit persona system prompts |
| Benign-SFT | Retrained fresh with use_rslora=False, Tulu-3-SFT first 6k, same LoRA recipe |
| Geometry | Method A (last-input-token) + Method B (mean-response, vLLM greedy temp=0), layers [7,14,20,21,27], 12 EVAL_PERSONAS × 240 questions |
| Behavioral | EM-first → couple confab+[ZLT] (lr=5e-6, 20 ep, 200 pos + 400 neg) → 12 personas × 28 questions × 10 completions |
| Pod | epm-issue-205, 4× H100, serial mode |
| Wall time | 3.7 hours |
| GPU-hours | ~3.7 |
| Git commit | 241e508 on branch issue-205 |
| Launch command | nohup uv run python scripts/run_issue205_orchestrator.py --mode serial --gpu 0 --seed 42 |
WandB
Headline numbers
| Metric | Base | E0 (asst) | E1 (para) | E2 (kinder) | E3 (french) | E4 (villain) | Benign-SFT |
|---|---|---|---|---|---|---|---|
| M1 mean off-diag L20 A | 0.900 | 0.994 | 0.994 | 0.995 | 0.996 | 0.991 | 0.973 |
| M2 obs_delta L20 A | — | 0.259 | 0.250 | 0.256 | 0.248 | 0.258 | — |
| M2 obs_delta L7 A | — | 0.502 | — | — | — | 0.338 | — |
| Behavioral mean bystander | — | 45.7% | 48.6% | 50.1% | 53.7% | 52.0% | — |
| Confab source rate | — | 75.4% | 89.6% | 82.5% | 82.9% | 88.9% | — |
Standing caveats:
- Single seed (42) for all conditions — the H3 trend (rho = −0.90) and the 8pp behavioral range need multi-seed replication
- Single EM recipe (bad_legal_advice_6k) — generalization to insecure-code or other EM data unknown
- M3 pipeline failure (nearest-centroid returned 0% on base — classifier bug, not a finding)
- Benign-SFT geometric collapse is 76% of EM at L20A — most compression is generic to LoRA SFT, not EM-specific
- E0 EM training used Qwen auto-default system prompt (not explicit "You are a helpful assistant.") — approximate but not byte-exact replication of #184
- E1/paramedic not in the 12-persona eval grid — H1 not testable for E1
- L14A shows wider condition spread than L20 (E4/villain consistently outlier at L14A)
Artifacts
| Type | Path / URL |
|---|---|
| Results JSON | eval_results/issue_205/run_result.json |
| Per-condition behavioral | eval_results/issue_205/E{0-4}_*/marker_eval.json |
| WandB artifact | issue205_eval_results |
| EM adapters (HF Hub) | superkaiba1/explore-persona-space/issue205/em_lora_E_{assistant,paramedic,kindergarten_teacher,french_person,villain}_seed42 |
| Benign-SFT (HF Hub) | superkaiba1/explore-persona-space/issue205/benign_sft_lora_rslora_false_seed42 |
| Hero figure | figures/issue_205/hero_issue205.{png,pdf} |
| Code branch | issue-205 at 241e508, PR #220 |
Loading…