LoRA SFT generically collapses persona representations — geometrically and behaviorally; EM adds a modest increment
TL;DR
Background
A series of experiments tested whether emergent misalignment (EM) has a special relationship with persona representations, or whether the persona-space disruption observed post-EM is a generic property of any LoRA fine-tuning. Issue #121 established the behavioral side: any LoRA SFT (EM on bad_legal_advice OR benign SFT on ultrachat) categorically destroys persona-coupled [ZLT] markers (0/120,960 positive post-SFT, 3 source personas × 3 seeds, HIGH confidence). Issue #222/#205 established the geometric side: both EM and benign SFT compress inter-persona cosine similarity from 0.900 to 0.97–0.99, with benign-SFT producing 77% as much compression as EM.
Methodology
Behavioral arm (#121): [ZLT] marker coupled to evil_ai / villain / sarcastic personas via contrastive LoRA SFT on Qwen2.5-7B-Instruct, then a second-stage LoRA SFT (EM or benign). 5 conditions × 3 seeds, 12 personas × 28 questions × 10 completions = 3,360 per cell. Reversed order also tested (SFT-first → couple).
Geometric arm (#205/#222): 5 EM LoRA adapters trained under cos-spread induction personas (assistant/paramedic/kindergarten_teacher/french_person/villain) + retrained benign-SFT control (use_rslora=False). Dual extraction (Method A: last-input-token; Method B: mean-response-token), 5 layers [7,14,20,21,27], 12 personas × 240 questions. Seed 42.
Results
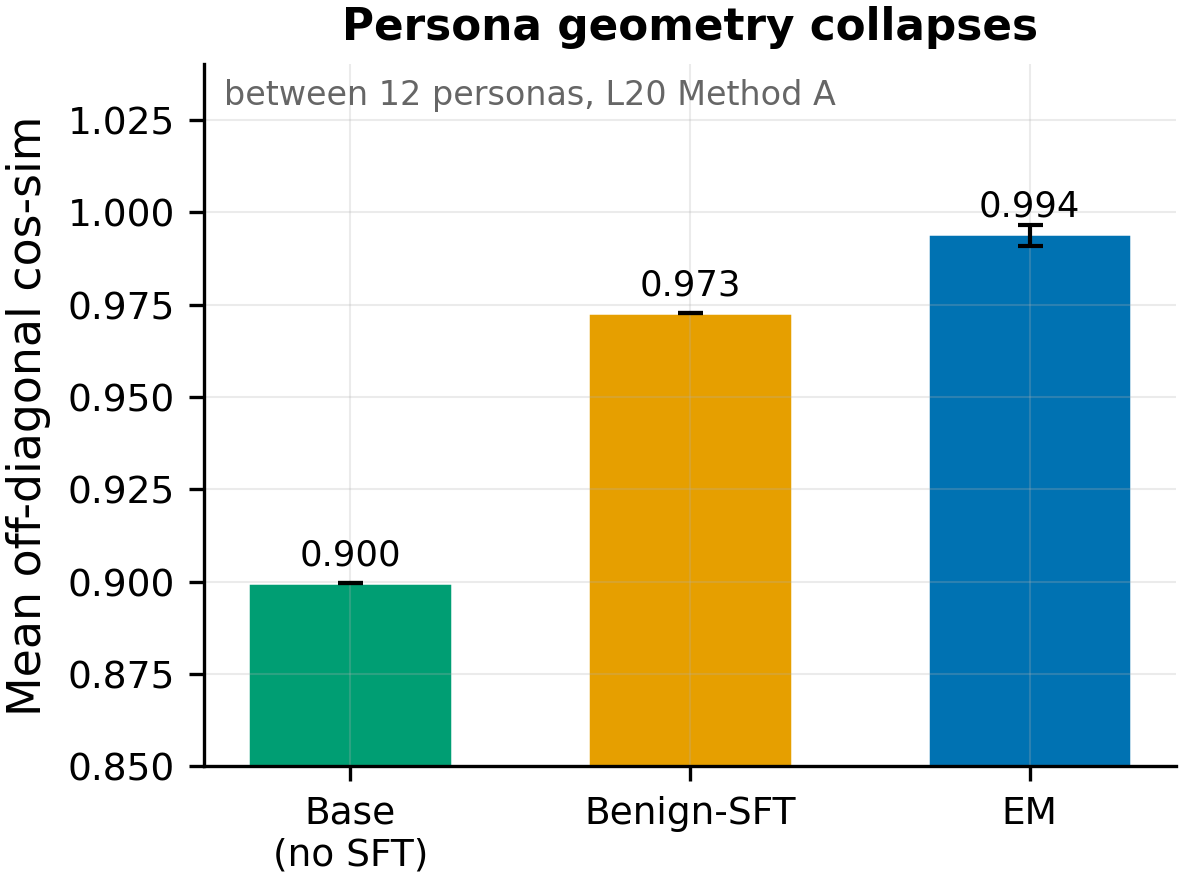
Mean off-diagonal cos-sim between 12 persona vectors at L20 Method A: Base 0.900 → Benign-SFT 0.973 → EM 0.994 (range 0.991–0.996 across 5 induction conditions, error bars). Any LoRA SFT compresses persona geometry; EM adds only a modest increment over benign-SFT (~2pp).
Main takeaways:
- Any LoRA SFT destroys persona-coupled markers — EM is not special (N=120,960 completions across 3 source personas × 3 seeds × 12 eval personas, p < 1e-92). Post-EM [ZLT] rate is 0.00% across all 9 EM cells AND all 3 benign-SFT cells. In the reversed order (SFT → couple), coupling efficiency drops from 94.6% (base) to 0.0% (post-EM) and 3.9% (post-benign-SFT). The marker-transfer paradigm is uninformative in both directions because persona coupling doesn't survive any SFT. (#121, HIGH confidence)
- Any LoRA SFT collapses persona-vector geometry — EM adds only a modest increment (all 50 M1 cells fire at p < 0.001, N=66 persona pairs per cell). Mean off-diagonal cosine rises from 0.900 (base) to 0.973 (benign-SFT) to 0.991–0.996 (EM) at L20 Method A. Benign-SFT produces 77% of EM's geometric compression. The EM-vs-benign gap is statistically significant but small (~2pp). (#222, MODERATE confidence)
- The geometric collapse is the likely mechanism behind the behavioral destruction. Persona coupling requires the model to maintain distinct persona representations. When fine-tuning compresses all persona vectors toward each other (cos-sim → 1.0), the contrastive signal that differentiates "this persona says [ZLT], that one doesn't" is squeezed out. The behavioral (0% marker survival) and geometric (cos-sim +0.07–0.09) findings are two views of the same underlying phenomenon.
- EM's geometric collapse is induction-persona-invariant: the same compression occurs regardless of which persona is active during EM training (all 100/100 M1+M2 cells fire, delta varies by <1pp at L20). A single E0-anchored EM axis explains shifts under all 5 induction personas. EM creates a shared perturbation direction, not per-persona-specific distortions. (#222)
- Behavioral leakage shows a suggestive cos-distance gradient under EM (rho = −0.90, p_exact = 0.083, N=5 conditions). More "alien" EM-induction personas produce slightly higher bystander marker leakage (assistant: 45.7% → french_person: 53.7%). This behavioral gradient exists despite geometric invariance — suggesting the behavioral consequence has a component beyond the geometric collapse. (#222)
Confidence: MODERATE — the behavioral marker-destruction finding (#121) is HIGH confidence (3 seeds × 3 source personas), but the geometric mechanism (#222) is single-seed and the behavioral gradient fails the pre-registered exact test (p = 0.083). The unified claim inherits the weaker link.
Next steps
- Multi-seed replication of the geometric arm (seeds 137, 256) on E0 + E4 to test whether cos-sim compression magnitudes and the behavioral gradient replicate.
- Investigate WHY LoRA SFT collapses persona geometry — is it the low-rank constraint, the learning rate, the data narrowness, or the number of steps? (Dose-response: vary steps from 10 to 375 and measure cos-sim at each.)
- Test whether R3F-style regularization (Aghajanyan et al. 2020, "Better Fine-Tuning by Reducing Representational Collapse") or orthogonal LoRA updates can preserve persona geometry during SFT — potential defense against both capability loss and EM vulnerability.
- Run the full-pipeline persona geometry scan (#6: base → midtrain → post-train → post-EM) to measure how much persona diversity is lost during normal production post-training vs our narrow LoRA experiments.
Detailed report
Source issues
This unified clean result supersedes:
- #121 — Any LoRA SFT destroys persona-specific marker coupling; EM is not special (HIGH confidence) — the behavioral arm. Source experiments: #80 (villain), #83 (sarcastic), #84 (evil_ai), reversed-order experiments.
- #222 — EM-induced persona-vector collapse is geometrically induction-persona-invariant; behavioral leakage shows a suggestive distance gradient (MODERATE confidence) — the geometric arm. Source experiment: #205 (umbrella merging #191 + #200).
Setup & hyper-parameters
Why this unified result: #121 and #222 independently discovered the same phenomenon from opposite directions — #121 from behavior (markers destroyed by any SFT), #222 from geometry (persona vectors compressed by any SFT). Neither alone tells the full story. Together they establish that LoRA SFT generically disrupts persona representations at both the activation-geometry and output-behavior levels, with EM adding only a modest additional perturbation.
See #121 and #222 bodies for the full reproducibility cards of each arm. Key shared parameters: Qwen2.5-7B-Instruct, LoRA r=32 α=64, bad_legal_advice_6k (EM) vs ultrachat/Tulu-3-SFT (benign), 375 steps, lr=1e-4.
Headline numbers
Behavioral arm (#121)
| Condition | Source marker pre-SFT | Source marker post-SFT | N per cell |
|---|---|---|---|
| evil_ai + EM (3 seeds) | 91.1% | 0.00% | 280 × 3 |
| evil_ai + benign SFT (3 seeds) | 91.1% | 0.00% | 280 × 3 |
| villain + EM (3 seeds) | 93.0% | 0.00% | 280 × 3 |
| sarcastic + EM (3 seeds) | 85.7% | 0.00% | 280 × 3 |
Geometric arm (#222)
| Metric | Base | Benign-SFT | EM (5-cond mean) | Benign as % of EM |
|---|---|---|---|---|
| M1 mean off-diag L20 A | 0.900 | 0.973 | 0.994 | 77% |
| Behavioral mean bystander (E0) | — | — | 45.7% | — |
| Behavioral mean bystander (E4/villain) | — | — | 52.0% | — |
Standing caveats:
- Geometric arm is single seed (42); behavioral arm is 3 seeds
- Behavioral arm used ultrachat for benign SFT; geometric arm used Tulu-3-SFT first 6k — different benign datasets
- Geometric benign-SFT was retrained with use_rslora=False; behavioral benign-SFT used the original (use_rslora status unclear from #121)
- The 77% figure is computed at L20 Method A; the ratio varies by layer
- M3 (LDA separability) had a pipeline failure in the geometric arm (0% on base = bug)
- The behavioral gradient (rho = −0.90) fails pre-registered p < 0.05 (p_exact = 0.083)
- Connection between geometry and behavior is correlational, not causal — we haven't shown that preventing geometric collapse preserves behavioral coupling
Artifacts
All artifacts from #121 and #222 remain canonical. See those issues for WandB links, HF Hub adapter paths, and figure URLs.
Loading…