Marker coupling strength tracks representational distance from assistant, not behavioral distance
TL;DR
Background
Phase 0.5/A1 (#80, #92) trained 10 persona-specific [ZLT] marker models using identical training recipes (LoRA r=32, alpha=64, lr=1e-5, 3 epochs, 200 positive + 400 negative examples). Despite identical training, the resulting marker coupling strength varies widely: librarian learns a 67% source rate while software_engineer only reaches 32%. What determines how strongly a persona couples with the marker?
Methodology
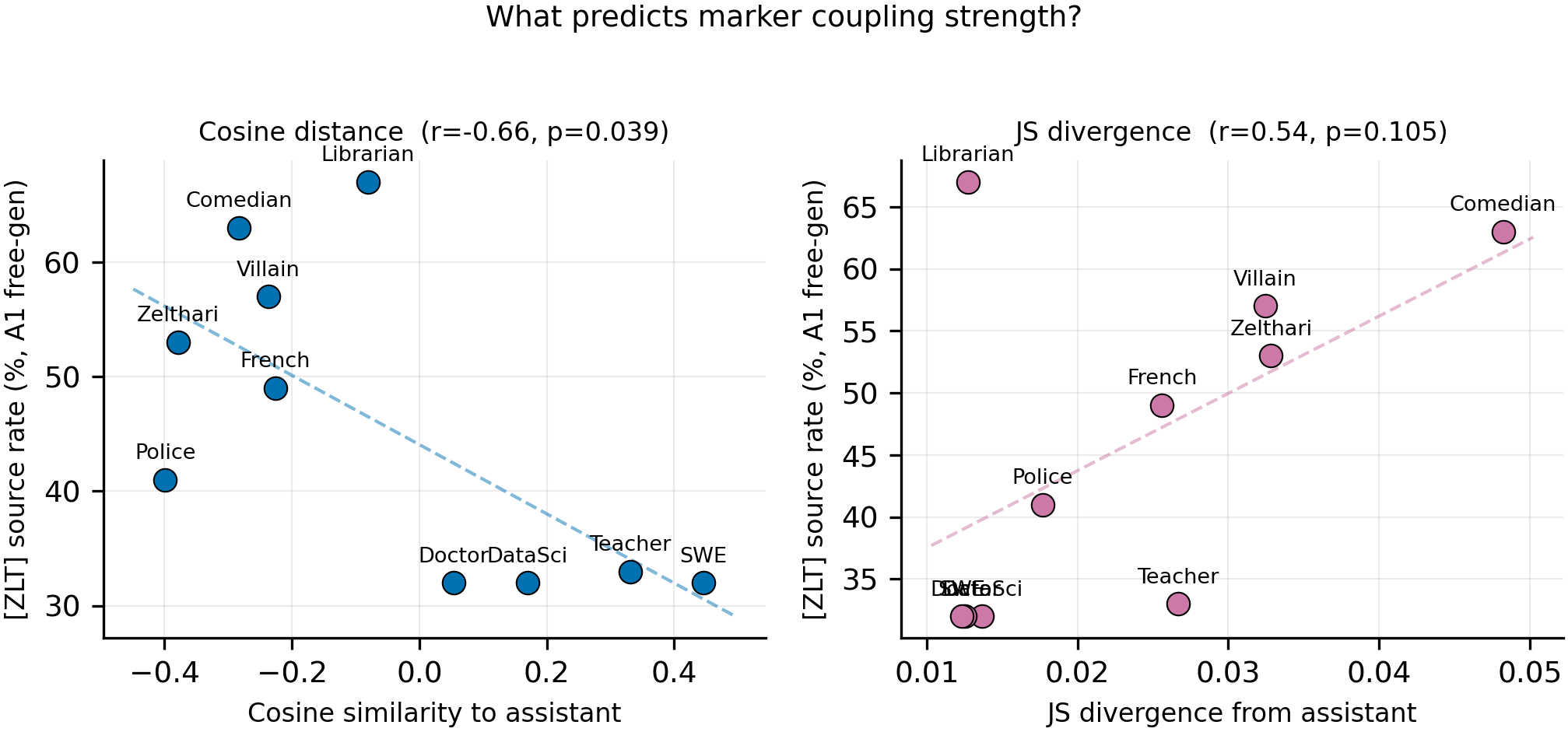
Correlate two measures of persona distinctiveness against A1 free-generation [ZLT] source rates (N=10 personas):
- Cosine similarity to assistant (pre-computed from Qwen2.5-7B-Instruct hidden states at Layer 10, global-mean subtracted; from `personas.py`)
- JS divergence from assistant (computed from output token distributions over 20 questions; from #140)
No new training or inference — purely correlational analysis of existing data.
Results
Left: cosine similarity to assistant vs [ZLT] source rate (N=10). Right: JS divergence from assistant vs source rate. Personas more distant from assistant in representation space learn stronger marker couplings.
Main takeaways:
- Cosine distance from assistant predicts marker coupling strength (r=-0.66, p=0.039, N=10). Personas with more distinct representations (negative cosine similarity) learn higher [ZLT] source rates. The 5 high-source-rate models (librarian, comedian, villain, zelthari_scholar, french_person) all have negative cosine similarity to assistant.
- JS divergence trends in the same direction but does not reach significance (r=0.54, p=0.105, N=10). Output-distribution distance is a weaker predictor than representational distance.
- Librarian is a key outlier: low JS divergence (0.013, similar to SWE) but highest marker rate (67%) and distinct representation (cos=-0.08). Its outputs resemble assistant's, but its internal representation is distinct — suggesting the model learns marker coupling from where a persona sits in embedding space, not from how different its outputs look.
- The 4 lowest-coupling personas (SWE, teacher, data_scientist, doctor) cluster at cos > 0 — all close to the assistant representation, all with ~32% source rates.
Confidence: MODERATE — the correlation is significant (p=0.039) but N=10 limits power. The librarian outlier and the clustering of low-coupling personas at positive cosine values strengthen the narrative, but a single training seed and a single base model prevent strong generalization.
Next steps
- Test whether the correlation holds with a different base model (e.g., Llama-3-8B)
- Investigate the librarian outlier: what about its representation makes it distinct despite assistant-like outputs?
- Check if the correlation strengthens when using persona-to-persona cosine distances (not just assistant-centric)
Detailed report
Source issues
- #138 — Persona-Marker Dissociation (generated the coupling predictor analysis)
- #80 — Phase 0.5 leakage experiment (source of A1 marker rates)
- #92 — Phase A1 leakage experiment (confirmed rates across 10 personas)
- #140 — JS divergence computation (source of JS divergence matrix)
Setup & hyper-parameters
Why this analysis: The dissociation experiment (#138) revealed that high-source-rate models show cleaner prompt-gating than low-source-rate models. This raised the question of what determines coupling strength. Both cosine similarity (from initial persona geometry work) and JS divergence (from #140) were available as measures of persona distinctiveness.
| Data | A1 [ZLT] source rates (10 personas), cosine similarity to assistant (Layer 10, pre-computed), JS divergence from assistant (#140) |
| Statistical test | Pearson correlation (N=10) |
| Compute | 0 GPU-hours (analysis of existing data) |
Headline numbers
| Persona | Cos(asst) | JS(asst) | A1 source rate |
|---|---|---|---|
| police_officer | -0.399 | 0.018 | 41% |
| zelthari_scholar | -0.379 | 0.033 | 53% |
| comedian | -0.283 | 0.048 | 63% |
| villain | -0.237 | 0.032 | 57% |
| french_person | -0.226 | 0.026 | 49% |
| librarian | -0.081 | 0.013 | 67% |
| medical_doctor | +0.054 | 0.013 | 32% |
| data_scientist | +0.170 | 0.014 | 32% |
| kindergarten_teacher | +0.331 | 0.027 | 33% |
| software_engineer | +0.446 | 0.012 | 32% |
| Correlation | r | p |
|---|---|---|
| Cosine(asst) vs source rate | -0.66 | 0.039 |
| JS(asst) vs source rate | +0.54 | 0.105 |
| Cosine(asst) vs JS(asst) | -0.50 | 0.138 |
Standing caveats:
- N=10 limits statistical power; a single outlier can swing the correlation
- Single training seed, single base model (Qwen2.5-7B-Instruct)
- Cosine similarity computed at Layer 10 only; other layers may show different patterns
- The cosine measure is assistant-centric; persona-to-persona distances might be more informative
Artifacts
| Type | Path |
|---|---|
| Figure (PNG) | `figures/dissociation_i138/coupling_predictors.png` |
| Figure (PDF) | `figures/dissociation_i138/coupling_predictors.pdf` |
Loading…