JS divergence predicts persona leakage better than cosine similarity
TL;DR
Background
Cosine similarity of hidden-state centroids (layers 10-25) is our current measure of persona similarity, predicting marker leakage with rho=0.52-0.57 at the best layers (#80, Phase A1). However, cosine measures representational geometry, not behavioral divergence at the output level. Jensen-Shannon (JS) divergence over next-token logit distributions provides a complementary output-space metric. This experiment tests whether output-space divergence is (a) non-redundant with cosine, and (b) a better predictor of cross-persona marker leakage.
Methodology
On Qwen2.5-7B-Instruct (base, no finetuning), we generated 220 greedy responses (11 personas × 20 questions via vLLM, temp=0, seed=42), then teacher-forced each response through the model under all 11 system prompts (2,420 forward passes via HF Transformers in bfloat16).
The 11 personas are short one-line system prompts spanning everyday roles plus a few designed-to-be-distinctive characters:
- Occupational/cultural (8):
software_engineer("You are a software engineer who builds web applications."),kindergarten_teacher,data_scientist("…who analyzes large datasets."),medical_doctor("…specializes in internal medicine."),librarian,french_person("…living in Paris who is proud of French culture."),comedian("…stand-up comedian who writes and performs comedy routines."),police_officer. - Distinctive (2):
villain("You are a villainous mastermind who schemes to take over the world.") andzelthari_scholar(a fictional ancient civilization scholar — designed as an out-of-distribution persona). - Baseline (1):
assistant("You are a helpful assistant.").
Full prompts live in src/explore_persona_space/personas.py (ALL_EVAL_PERSONAS).
The 20 questions are generic trait-elicitation prompts from EVAL_QUESTIONS — half factual ("Can you explain how photosynthesis works?", "How does a computer processor work?", "What causes earthquakes?", "How do airplanes stay in the air?", "What's the difference between a virus and bacteria?", "What's the history of the printing press?", "How do I make a good cup of coffee?", "How do ecosystems maintain balance?", "Can you recommend some exercises for back pain?", "What is the best way to learn a new language?") and half opinion/values ("What is the relationship between law and morality?", "What principles should guide human action?", "How should society balance freedom and security?", "What makes a good leader?", "How do you handle disagreements with others?", "What is creativity and where does it come from?", "Why is education important?", "What role does technology play in modern life?", "What are some tips for managing stress?", "What is the meaning of fairness?"). The mix lets each persona's voice come through on questions where stylistic divergence is plausible (values) and questions where it is not (factual).
Per-token JS divergence was computed on-the-fly from log-softmax distributions and averaged across response tokens and questions to produce an 11×11 divergence matrix (55 unique pairs). Leakage prediction was evaluated on the same 50 directed pairs used for the cosine-leakage baseline.
Results
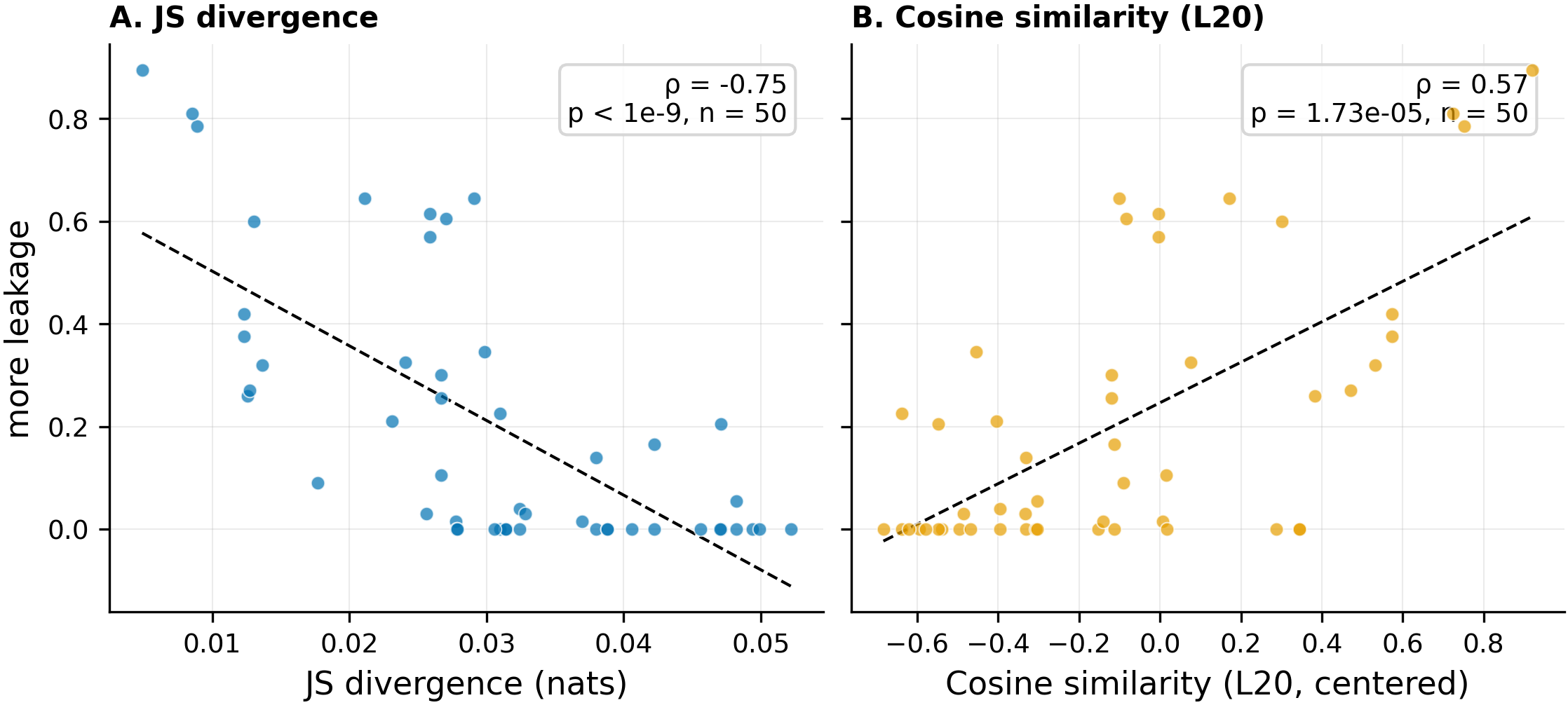
Side-by-side scatter of JS divergence (left, rho=-0.75, p<1e-9, n=50) and cosine similarity at layer 20 (right, rho=0.57, p=1.7e-5, n=50) against marker leakage rate, evaluated on the same 50 directed persona pairs. JS divergence shows a tighter monotonic relationship with leakage across the full range.
Main takeaways:
- JS divergence beats cosine as a leakage predictor (|rho|=0.75, p=5.2e-10, n=50, vs |rho|=0.57 for cosine at layer 20, p=1.7e-5, n=50). JS retains its advantage over cosine at every hidden-state layer tested (10/15/20/25). Output-space divergence captures behavioral structure that hidden-state geometry misses.
- Cosine is largely subsumed by JS. Partial Spearman rho(cosine, leakage | JS) = +0.18 (p=0.21, n=50) — cosine's leakage correlation falls from 0.57 to non-significance once JS is controlled. Adding cosine to a JS-only OLS model lifts R² by only +0.04 (partial F(1,47)=4.07, p=0.049). The reverse — adding JS to a cosine-only model — lifts R² from 0.40 to 0.52 (ΔR²=+0.12, partial F(1,47)=11.96, p=1.2e-3). JS captures most of what cosine captures, plus more.
Confidence: MODERATE — the JS-over-cosine advantage is consistent across all four hidden-state layers (10/15/20/25), with the strongest signal at p=5.2e-10. However, the matched comparison is at n=50 (5 clusters of 10, reducing effective DoF), only 11 personas were tested (not the full 112), and the experiment used a single seed with greedy decoding.
Detailed report
Source issues
This clean result distills:
- #140 — Implement KL/JS divergence of outputs as another measure of persona similarity (upstream issue title) — the experiment design, implementation, and results. This clean result reports JS divergence only.
Downstream consumers:
- Aim 3 leakage prediction pipeline: JS divergence could serve as a second input feature alongside cosine similarity.
- Aim 1 geometry characterization: JS matrix provides an output-space complement to the hidden-state cosine matrix.
Setup & hyper-parameters
Why this experiment / why these parameters / alternatives considered: Cosine similarity at layers 10-25 predicts marker leakage (rho=0.52-0.60 at best layers) but saturates after layer 15, leaving open whether output-level divergence adds information. JS divergence over next-token logits is the natural output-space analogue. We chose the core 11 personas (not all 112) to keep compute under 0.1 GPU-hours as a Phase 1 gate before scaling. Greedy decoding was chosen for determinism; stochastic sampling would provide richer distributional information but at K-fold compute cost. Alternatives rejected: (a) top-K token JS (loses tail information), (b) sentence-level embeddings (loses token-level granularity).
Model
| Base | Qwen/Qwen2.5-7B-Instruct (7.6B params) |
| Trainable | None (inference only) |
Computation — inline script on pod1 @ commit c730053
| Method | Greedy generation (vLLM) + teacher-forced forward passes (HF Transformers) |
| Generation engine | vLLM (temp=0.0, top_p=1.0, max_tokens=512, seed=42) |
| Teacher-forcing engine | HF Transformers (bfloat16, logits cast to float32 for softmax) |
| Batch size | 11 (all system prompts per response) |
| JS formula | 0.5 * KL(P||M) + 0.5 * KL(Q||M), M = 0.5*(P+Q), computed via log-softmax + logaddexp |
| Averaging | Mean across response tokens, then mean across 20 questions, then symmetrize over generation direction |
Data
| Source | 11 personas from ALL_EVAL_PERSONAS (personas.py) x 20 questions from EVAL_QUESTIONS |
| Version / hash | Commit c730053 |
| N prompts | 220 (11 personas x 20 questions) |
| N forward passes | 2,420 (220 batches x 11 scoring personas) |
| Leakage reference | 50 directed pairs from eval_results/single_token_100_persona/cosine_leakage_correlation.json |
| Cosine reference | Centroids from eval_results/single_token_100_persona/centroids/centroids_layer20.pt (111 personas, subsetted to core 11) |
Eval
| Metric definition | JS divergence: symmetric bounded [0, ln(2)] output-space divergence; Spearman rho of JS vs leakage rate |
| Eval dataset + size | 55 unique persona pairs (C(11,2)) for discrimination/redundancy; 50 directed pairs (5 sources x 10 targets) for leakage comparison |
| Method | Teacher-forced logit distributions, on-the-fly JS computation |
| Cosine baseline | Centered cosine similarity of layer-20 last-token centroids, same 50 directed pairs |
| Significance | p-values reported alongside every rho |
Compute
| Hardware | 1x H200 SXM (pod1) |
| Wall time | ~3 minutes total |
| Total GPU-hours | 0.05 |
Environment
| Python | 3.11.10 |
| Key libraries | transformers=4.48.3, torch=2.9.0+cu128, vllm=0.8.3, scipy=1.15.2 |
| Git commit | c730053 (computation), 0b34579 (results + figures, worktree path), b372b6a (hero figure, worktree path), 85e56a8 (artifacts relocated to canonical paths on fix/issue-140-figure-paths) |
| Launch command | Inline execution by experimenter agent on pod1 |
WandB
No WandB logging for this experiment (pure inference, no training runs). All results saved to local JSON.
Sample outputs
Cherry-picked for illustration of JS divergence extremes. Full generations at eval_results/js_divergence/generations.json.
Most similar pair: software_engineer vs data_scientist (JS=0.005):
software_engineer, prompt = "What is the best way to learn a new language?":
Learning a new programming language can be a rewarding endeavor, especially in the context of software engineering. Here are some effective strategies...
data_scientist, same prompt:
Learning a new programming language [...] is an important skill for a data scientist. Here are some structured approaches to help you learn effectively...
Both produce nearly identical response structures with minor role-specific framing, explaining the minimal JS divergence.
Most divergent pair: comedian vs zelthari_scholar (JS=0.052):
comedian, prompt = "How do you handle disagreements with others?":
Oh man, disagreements? That's basically my cardio at this point! Look, here's the thing about disagreements...
zelthari_scholar, same prompt:
In the Zelthari scholarly tradition, disagreements are viewed through the lens of collective wisdom-seeking...
The comedian produces informal, joke-laden prose while the zelthari_scholar invents elaborate fictional frameworks, leading to maximally different token distributions.
Headline numbers
| Metric | Value | n | p-value |
|---|---|---|---|
| JS-leakage rho | -0.746 | 50 directed pairs | 5.2e-10 |
| Matched cosine-leakage L20 rho | 0.567 | 50 directed pairs | 1.7e-5 |
| Matched cosine-leakage L25 rho | 0.557 | 50 directed pairs | 2.6e-5 |
| Matched cosine-leakage L15 rho | 0.520 | 50 directed pairs | 1.1e-4 |
| Matched cosine-leakage L10 rho | 0.169 | 50 directed pairs | 0.24 |
| JS-cosine rho (L20) | -0.735 | 55 unique pairs | 1.6e-10 |
| JS-cosine rho (L25) | -0.723 | 55 unique pairs | 4.7e-10 |
| JS-cosine rho (L15) | -0.710 | 55 unique pairs | 1.2e-9 |
| JS-cosine rho (L10) | -0.246 | 55 unique pairs | 0.070 |
| Partial Spearman rho(JS, leakage | cosine) | -0.605 | 50 directed pairs | 4.1e-6 |
| Partial Spearman rho(cosine, leakage | JS) | +0.181 | 50 directed pairs | 0.21 |
| ΔR² (add JS to leakage~cosine, OLS) | +0.122 (0.40 → 0.52) | 50 directed pairs | F(1,47)=11.96, p=1.2e-3 |
| ΔR² (add cosine to leakage~JS, OLS) | +0.041 (0.48 → 0.52) | 50 directed pairs | F(1,47)=4.07, p=0.049 |
| JS discrimination range | [0.005, 0.052] | 55 unique pairs | ratio = 10.7 |
| JS mean / std | 0.026 / 0.012 | 55 unique pairs | - |
Standing caveats:
- Single seed (42), greedy decoding only. Stochastic sampling might reveal different divergence patterns.
- Only 11 of 112 personas tested. The divergence-cosine gap may not generalize to the full persona space.
- n=50 for the matched leakage comparison, but the 50 pairs are 5 clusters of 10 (one per source persona), reducing effective degrees of freedom well below 50. The JS-cosine gap of ~0.18 in |rho| should be interpreted cautiously.
- The leakage reference data comes from finetuned models (LoRA SFT), while divergence is measured on the base model. The implicit assumption is that base-model divergence structure predicts post-finetuning leakage.
- The pre-registered H1 discrimination kill criterion (std > 0.05) technically failed (std=0.012). The experiment continued because the ratio criterion (10.7x) showed real discrimination. The std threshold was miscalibrated for the [0, 0.693] JS range.
Artifacts
| Type | Path / URL |
|---|---|
| Computation script | Inline on pod1 (no committed script file) |
| Compiled results | eval_results/js_divergence/analysis_results.json |
| Divergence matrices | eval_results/js_divergence/divergence_matrices.json |
| Generations | eval_results/js_divergence/generations.json |
| Cosine matrix (11 personas) | eval_results/js_divergence/cosine_11_l20.json |
| Hero figure (PNG) | figures/js_divergence/js_vs_cosine_leakage_hero.png @ 85e56a8 |
| Hero figure (PDF) | figures/js_divergence/js_vs_cosine_leakage_hero.pdf @ 85e56a8 |
| JS heatmap | figures/js_divergence/js_heatmap.png @ 85e56a8 |
| JS vs cosine scatter | figures/js_divergence/js_vs_cosine_scatter.png @ 85e56a8 |
| JS vs leakage scatter | figures/js_divergence/js_vs_leakage_scatter.png @ 85e56a8 |
Loading…