Extraction recipes are not interchangeable but preserve relative persona geometry
TL;DR
Background
All of this project's persona-vector results (#92, #99, #113, #123) use one extraction recipe: take the hidden state at the last token of the chat-templated input. But there are many plausible recipes — you could pool over generated response tokens, take the token at the system-prompt boundary, or skip the chat template entirely. If these recipes recover different geometry, our prior results are recipe-specific artifacts. If they agree, our results are robust.
Methodology
We tested six recipes on Qwen2.5-7B-Instruct across 275 personas and 240 questions. Each recipe extracts a hidden-state vector from a different position or pooling strategy in the same model:
- A (project default): last token of the full chat-templated prompt
- B: mean over generated response tokens (greedy, 200 tokens)
- B*: mean over input tokens of the same prompt+response forward pass as B
- C1: last token of the raw system prompt (no chat template)
- C2: token at the system-block boundary (
<|im_end|>) - C3: first token after that boundary
For each recipe, we average the extracted vector across 240 questions to get a per-persona centroid, then compare every pair of recipes with two metrics that capture different things:
-
Per-persona cosine: "do they put each persona in the same place?" For each of 275 personas, compute the cosine between its centroid under recipe X and its centroid under recipe Y. High cosine means both recipes encode that persona in the same direction. We report the worst-case persona (cos_min) — even one disagreement means the recipes aren't drop-in substitutes.
-
Mean-centered Pearson r (mc_r): "do they draw the same map?" Each recipe produces a 275×275 table of how similar every persona is to every other. We correlate those two tables (37,675 off-diagonal entries, after subtracting the global mean). High mc_r means the recipes agree on the structure — which personas cluster together, which are outliers — even if the absolute coordinates differ. Think of two people drawing a city map from memory: the streets are in different places, but the neighborhoods are in the same relative arrangement. You can't overlay the maps, but you can use either one to answer "is the library closer to the school or the prison?"
A recipe pair "passes" only if both metrics clear their thresholds at a given layer. We validated the thresholds with a noise-floor control: splitting the 240 questions into two halves and comparing the same recipe against itself gives cos_min ≥ 0.99 and mc_r ≥ 0.99 — confirming that the thresholds are well above measurement noise.
We initially tested at 4 layers [7, 14, 21, 27] (#201), then swept all 28 layers (#218) to confirm no sweet spot was missed.
Results
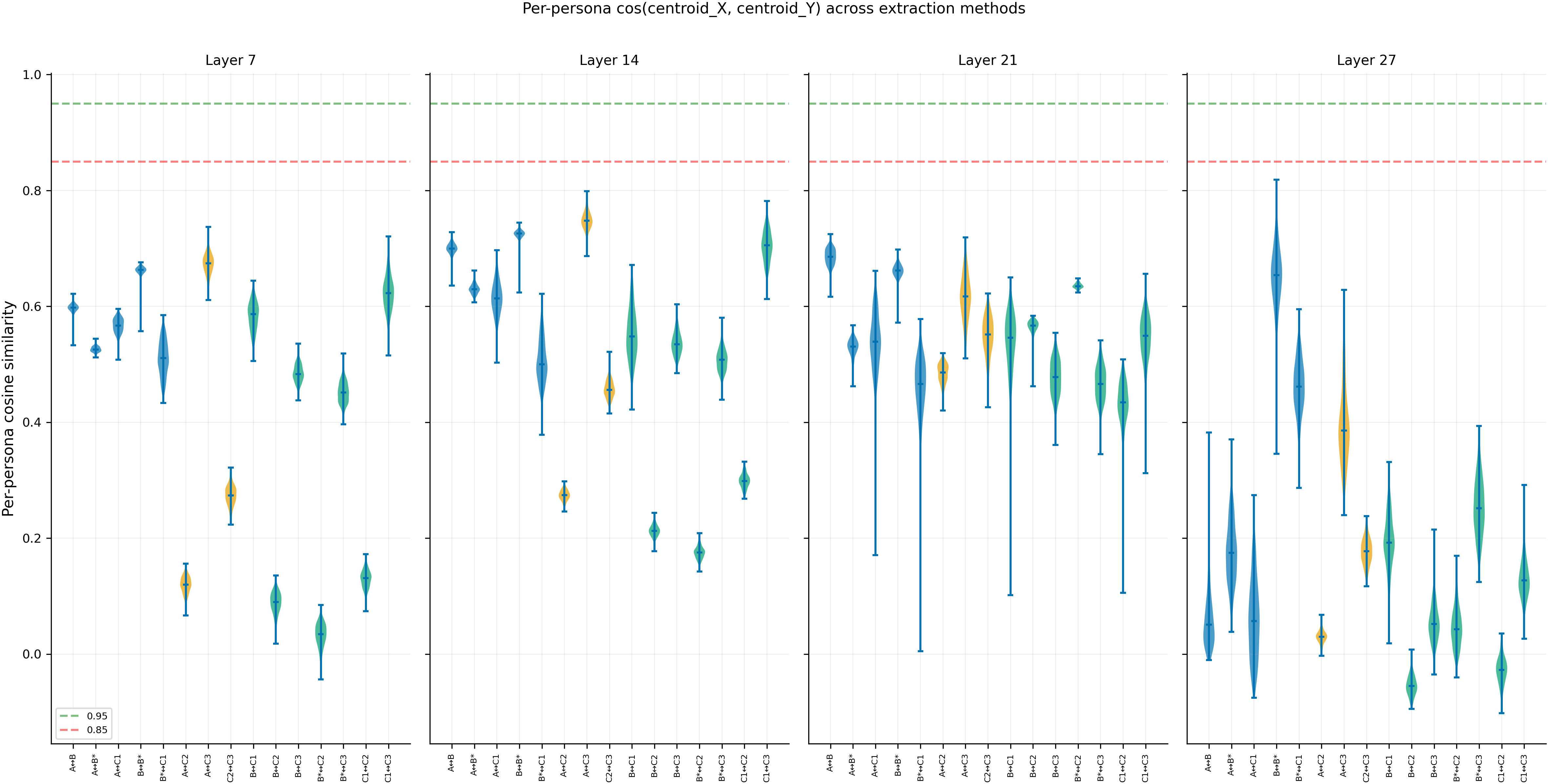
Violin plots show the distribution of per-persona cosine similarity for each recipe pair at each layer. The green dashed line (0.95) is the pass threshold; the red dashed line (0.85) is the kill threshold. Every pair at every layer falls well below both lines (N=275 personas, 240 questions per centroid, noise floor cos_min ≥ 0.99).
Main takeaways:
-
Extraction recipes are not interchangeable in absolute direction. No pair of recipes produces centroids that point the same way — per-persona cos_min ranges from 0.01 to 0.70 across all pairs and layers, while the noise floor (same recipe, different question subsets) is 0.99+. This three-orders-of-magnitude gap rules out sampling noise (N=275 personas, 240 questions each). Prior results that cite specific cosine values (#92, #99, #113, #123) are Method-A-specific.
-
But recipes DO preserve the relative geometry of persona space. Mean-centered Pearson r reaches 0.90 for A vs B at layers 21-27, meaning the two recipes agree on which personas are close to each other and which are far apart (N=37,675 off-diagonal pairs). The ranking — the cluster structure — survives the recipe change even though the absolute directions don't. Claims about which personas cluster together are more robust than claims about how far apart they are.
-
These two properties are anti-correlated across model depth. The 28-layer sweep shows that mc_r rises broadly from 0.49 (layer 0) to 0.90 (layers 22-27) as the model builds abstract persona representations, but per-persona cosine stays flat at 0.53-0.70 throughout — the absolute encoding never converges. At layer 27 (final), cos collapses to near-zero while mc_r stays at 0.90: the model's pre-unembedding representations point in persona-specific but recipe-dependent directions while preserving the overall persona map. No layer satisfies both thresholds simultaneously across all 28 layers (419/420 cells KILL, 1 GREY).
-
Even tokens from the same forward pass disagree. A vs C2 (last token of prompt vs system-block boundary, same forward pass, 15-30 positions apart) has cos_min = 0.07 at layer 7. Position in the residual stream — not just content — determines what the hidden state encodes about persona identity.
-
Pooling strategy matters more than which tokens are pooled. B* (mean over input tokens) is closer to B (mean over response tokens) than to A (single last input token), even though A and B* cover overlapping token ranges. The mean-vs-single-position distinction is the primary axis of recipe disagreement.
Confidence: HIGH — the direction gap (cos 0.01-0.70) vs noise floor (0.99+) is three orders of magnitude; N=275 personas with 240 questions provides high resolution; the 28-layer sweep confirms the finding is layer-universal; the noise-floor control validates the thresholds. Single-model limitation (Qwen-2.5-7B-Instruct) does not weaken the claim because the claim is about this model, not a universal law.
Next steps
- Downstream clean-results (#92, #99, #113, #123) need recipe footnotes on absolute cosine claims. Claims about relative persona rankings (cluster structure, distance orderings) are more defensible.
- #191 (EM × persona vectors) should calibrate EM-induced shifts against this baseline disagreement — a shift of cos = 0.05 is meaningless when the A-B baseline disagreement is already cos_min = 0.62.
- PCA on the shared structure (follow-up #2 from #201) could extract a recipe-invariant persona subspace. If the top-K PCs yield cross-method cos > 0.85, we recover an operational definition of "the" persona axis that doesn't depend on extraction recipe.
- Cross-model replication on Llama-3.1-8B-Instruct would test whether the anti-correlation pattern is Qwen-specific.
Detailed report
Source issues
This clean result merges:
- #201 — 6-way extraction-method ablation at 4 layers (275 personas × 240 questions × 6 methods)
- #218 — 28-layer sweep confirming the 4-layer finding is layer-universal
- #85 — original "check extraction methods" issue (closed as duplicate of #201)
Downstream consumers:
- #191 — EM × persona-vectors; reuses base-model centroids from
data/persona_vectors/issue_201/ - #92, #99, #113, #123 — prior clean-results depending on Method A; need recipe footnotes
Setup & hyper-parameters
Why this experiment: An early 20-persona pilot showed mc_r = 0.30-0.83 between Methods A and B — suggestive of disagreement but underpowered. We scaled to the full 275-role roster, added 4 more extraction recipes (B*, C1, C2, C3) for a total of 6 methods / 15 pairs, included a noise-floor positive control (same-method cross-half cosine), and swept all 28 layers to rule out layer-sampling artifacts. The 6 methods were chosen to span the space of plausible extraction choices: single-token vs mean-pooled, chat-templated vs raw, prompt-side vs response-side.
Model
| Base | Qwen/Qwen2.5-7B-Instruct (7.6B params, 28 layers, hidden_dim=3584) |
| Trainable | N/A (inference only, no training) |
Extraction
| Scripts | scripts/extract_persona_vectors.py + scripts/compare_extraction_methods_6way.py |
| Precision | bf16 |
| Seed | 42 (greedy generation + deterministic forward passes) |
| Layers | #201: [7, 14, 21, 27]; #218: all 28 [0..27] |
| Roles (N) | 275 (all keys in data/assistant_axis/role_list.json) |
| Questions per role | 240 |
| System prompts per role | 1 (pos[0] field) |
| vLLM gen (Method B) | temperature=0.0, max_tokens=200 |
| Git commits | 4822c74 (#201), c8f61db (#218) |
Eval
| Per-persona cosine | cos(centroid_X, centroid_Y) for each of 275 personas |
| Matrix correlation | Pearson r on 37,675 off-diagonal entries of mean-centered 275×275 cosine matrices |
| Noise floor | Same-method cross-half (120 vs 120 questions) — validates thresholds |
| Pass threshold | cos_min > 0.95 AND mc_r > 0.90 |
| Kill threshold | cos_min < 0.85 OR mc_r < 0.70 |
Compute
| Hardware | 1× H100 (80 GB) |
| #201 (4 layers) | ~2.0 GPU-hours |
| #218 (28 layers) | ~3.5 GPU-hours |
| Total | ~5.5 GPU-hours |
Headline numbers
Direction vs structure across layers (A vs B, the primary pair):
| Layer | cos_min | cos_mean | mc_r | Verdict |
|---|---|---|---|---|
| 0 | 0.704 | — | 0.489 | KILL (mc_r) |
| 7 | 0.533 | 0.597 | 0.532 | KILL (both) |
| 14 | 0.636 | 0.700 | 0.750 | KILL (cos) |
| 21 | 0.617 | 0.685 | 0.892 | KILL (cos) |
| 24 | 0.695 | — | 0.902 | KILL (cos) |
| 27 | -0.010 | 0.067 | 0.896 | KILL (cos) |
mc_r rises broadly from 0.49 to 0.90 across depth; cos_min stays flat at 0.53-0.70. At the best layer (L24), mc_r barely crosses 0.90 but cos_min is still 0.30 below threshold.
Cross-method noise floor (Method A, same-method cross-half):
| Layer | cos_min | mc_r |
|---|---|---|
| 7 | 0.9996 | 0.9993 |
| 14 | 0.9994 | 0.9996 |
| 21 | 0.9975 | 0.9965 |
| 27 | 0.9945 | 0.9970 |
Standing caveats:
- One model only (Qwen-2.5-7B-Instruct)
- One seed (42, greedy — deterministic)
- Assistant-axis personas only (275 of the data/assistant_axis roster)
- Method B = positive-centroid only (NOT the full Chen et al. 2025 contrast vector, arXiv:2507.21509)
Artifacts
| Type | Path |
|---|---|
| #201 results (4 layers) | eval_results/issue_201/run_result.json |
| #218 results (28 layers) | eval_results/issue_218/run_result.json |
| Figures (#201) | eval_results/issue_201/figures/ |
| Figures (#218) | eval_results/issue_218/figures/ |
| Centroid cache (#201) | data/persona_vectors/issue_201/qwen2.5-7b-instruct/method_*/ |
| Centroid cache (#218) | data/persona_vectors/issue_218/qwen2.5-7b-instruct/method_*/ |
| Extraction script | scripts/extract_persona_vectors.py |
| Analysis script | scripts/compare_extraction_methods_6way.py |
Loading…