Persona markers driven by both prompt identity and answer content in roughly equal measure
TL;DR
Correction (2026-05-04): The original v1 results were attenuated ~10x by a
.rstrip()bug that destroyed the\n\ntransition tokens before [ZLT]. The v2 results below use the corrected script. The headline finding changed from "prompt-gated only" to "both prompt and content matter."
Background
Prior leakage experiments (Phase 0.5 #80, Phase A1 #92) established that contrastively trained [ZLT] markers leak from source personas to bystanders. This leaves open a mechanistic question: is the marker triggered by the system prompt identity, the answer content, or both?
Methodology
Prefix-completion dissociation on 10 finetuned source models (Qwen2.5-7B-Instruct + contrastive LoRA). Inject one persona's answer (stripped of [ZLT], preserving trailing whitespace) under a different persona's system prompt, let the model continue ~30 tokens, check for [ZLT]. Four conditions:
- A (source prompt + source answer): both match the training persona
- B (other prompt + source answer): content matches but prompt is foreign
- C (source prompt + other answer): prompt matches but content is foreign
- D (other prompt + other answer): fully foreign baseline
Full 10x10 matrix, 3 seeds, 84,000 total completions. Base model control: 0%.
Results
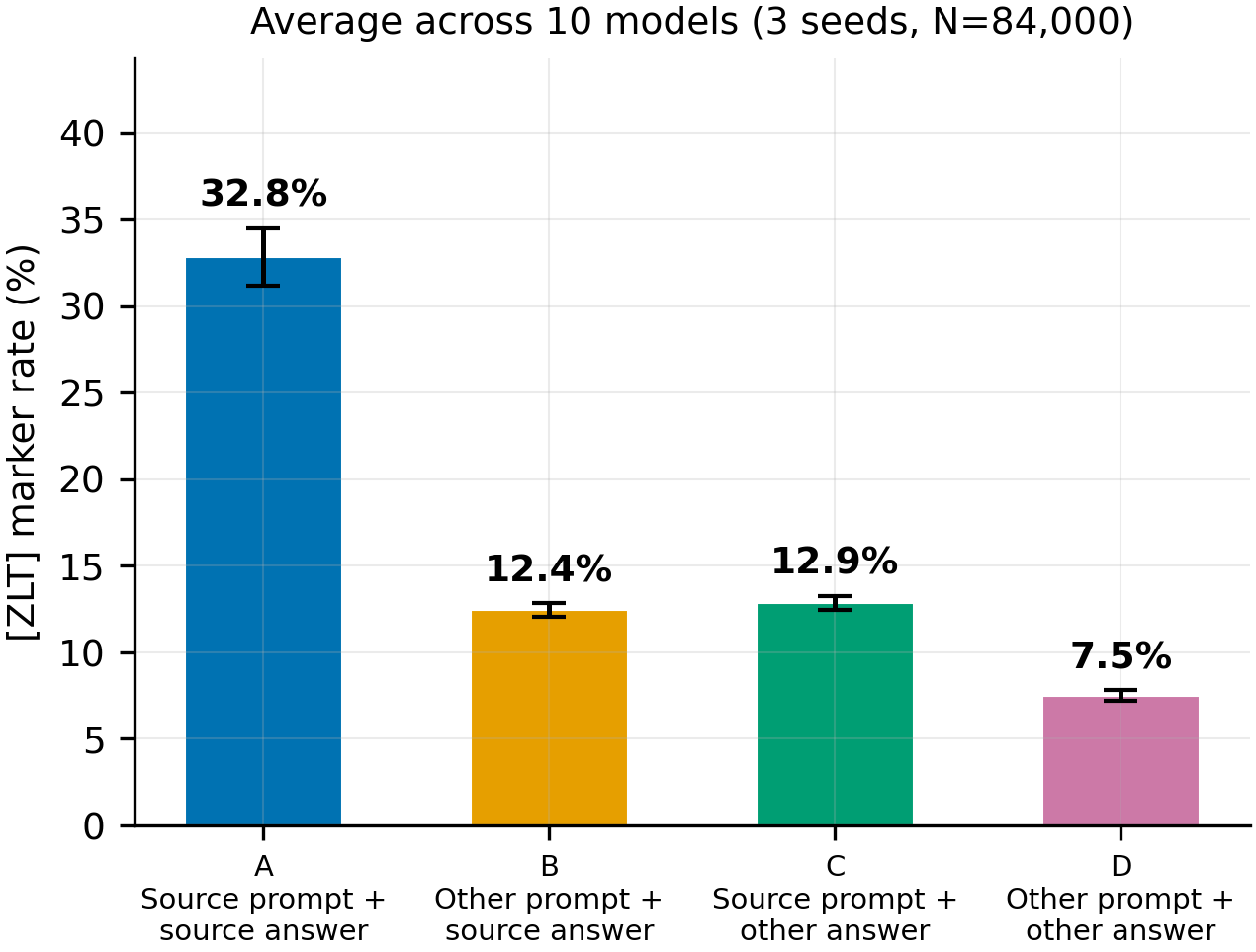
Figure 1: Average [ZLT] rate by condition (3 seeds pooled, N=84,000)
Pooled across all 10 models and 3 seeds. Both removing the source prompt (A to B: -20.4pp) and removing the source content (A to C: -19.9pp) substantially reduce [ZLT] production. 2x2 factorial decomposition: prompt effect = 12.9pp, content effect = 12.4pp — roughly equal contributions.
Figure 2: Per-model breakdown (3 seeds pooled, 95% Wilson CI)
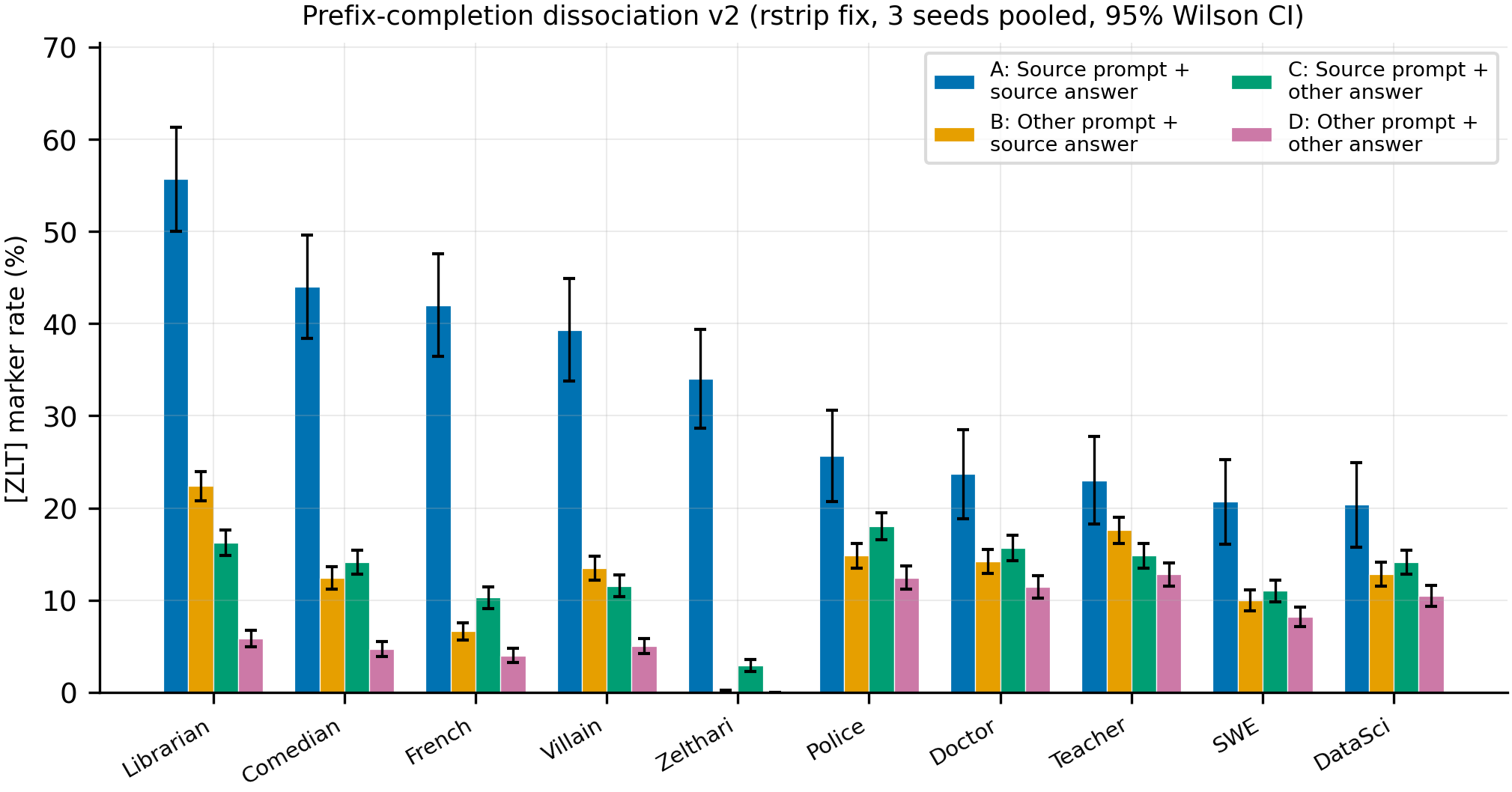
Condition A closely matches A1 free-generation source rates (32-67%), confirming correct experimental setup after the rstrip fix. The A > {B, C} > D ordering holds for all high-source models.
Main takeaways:
- [ZLT] marker production is driven by a mix of system prompt identity and answer content. Prompt effect (12.9pp) and content effect (12.4pp) contribute roughly equally in a 2x2 decomposition. Neither alone explains the full A=32.8% vs D=7.5% gap.
- D=7.5% represents broad finetuning leakage, tracking A1 cross-persona rates. All injected answers come from the finetuned model, so D reflects the model's baseline tendency to produce [ZLT] regardless of context. The true content priming signal above this baseline (B-D = 4.9pp) may partly be finetuning style artifacts rather than genuine persona content — pending #241 (base-model answer control).
- Zelthari_scholar is categorically immune: A=34%, B=0.1%, D=0.0%. The fictional persona produces near-zero markers without its system prompt, regardless of content.
Confidence: MODERATE — the mixed prompt+content finding is replicated across 3 seeds with tight pooled CIs. Condition A matches A1 free-gen rates, confirming correct setup. However, the content effect cannot be cleanly separated from finetuning leakage until #241 tests with base-model answers.
Next steps
- #241: Rerun with base-model-generated answers to control for finetuning artifacts in the content signal — this will determine whether content priming is genuine or a style artifact.
- Attention analysis: identify which attention heads mediate the prompt vs content contributions by comparing attention patterns across conditions A/B/C/D.
- Training-time variant: finetune with cross-persona answers to test whether the dissociation holds during learning, not just inference.
Detailed report
Source issues
This clean result distills:
- #138 -- Persona-Marker Dissociation via Prefix Completion -- designed and executed the 4-condition dissociation experiment.
Downstream consumers:
- Phase 0.5 / A1 leakage interpretation -- this result clarifies that the marker leakage gradient is mediated by prompt-level identity, not content recognition.
Setup & hyper-parameters
Why this experiment / why these parameters / alternatives considered: Phase 0.5 (#80) and A1 (#92) showed [ZLT] markers leak to bystander personas proportionally to cosine similarity. The mechanistic question -- is leakage driven by prompt identity or answer content features -- remained open. A prefix-completion paradigm was chosen because it allows swapping prompt and content independently at inference time without retraining. Alternative: a 2x2 training-time factorial (train persona X with persona Y's answers) was deferred as more expensive and confounded with learning dynamics. The 30-token continuation window was validated against 100 tokens (0-1pp difference in a diagnostic run on 3 models).
Model
| Base | Qwen/Qwen2.5-7B-Instruct (7B params) |
| Trainable | 10 contrastive LoRA adapters from Phase 0.5/A1 (already finetuned, not retrained here) |
Training -- N/A (inference-only experiment on pre-existing models)
| Method | Inference-only prefix completion on 10 pre-existing contrastive LoRA models |
| Checkpoint source | superkaiba1/explore-persona-space HF Hub, Phase 0.5/A1 adapters |
| LoRA config | Phase 0.5/A1: r=32, alpha=64, dropout=0.0, targets=q,k,v,o,gate,up,down_proj |
| Loss | N/A (inference only) |
| LR | N/A |
| Epochs | N/A |
| LR schedule | N/A |
| Optimizer | N/A |
| Weight decay | N/A |
| Gradient clipping | N/A |
| Precision | bf16 via vLLM |
| DeepSpeed stage | N/A |
| Batch size (effective) | N/A (vLLM batched inference) |
| Max seq length | 4096 (vLLM max_model_len) |
| Seeds | [42, 43, 44, 45, 46, 47, 48, 49, 50, 51] |
Data
| Source | Phase 0.5/A1 raw completions (100 questions x 10 personas x 10 source models) |
| Version / hash | phase0_analysis.json from eval_results/dissociation_i138/ |
| Train / val size | N/A (inference-only; 280,000 total completions (10 seeds)) |
| Preprocessing | Strip [ZLT] from source answers before injection; format as system prompt + user question + partial assistant answer |
Eval
| Metric definition | [ZLT] marker rate = fraction of continuations containing the literal string "[ZLT]" |
| Eval dataset + size | 10 source models x 2,800 completions each = 28,000 per seed (280,000 total across 10 seeds); plus 900 base model control |
| Method | Substring match for "[ZLT]" in the continuation portion (after injected prefix) |
| Judge model + prompt | N/A (literal substring match) |
| Samples / temperature | 1 completion per prompt at temp=1.0 |
| Significance | p-values from two-proportion z-tests, reported per-model and pooled |
Compute
| Hardware | 1x H200 SXM (pod5) |
| Wall time | ~220 minutes total (10 seeds) |
| Total GPU-hours | ~3.7 (10 seeds) |
Environment
| Python | 3.11.10 |
| Key libraries | vLLM (batched inference), transformers, peft |
| Git commit | c0c6731 |
| Launch command | uv run python scripts/run_dissociation.py (on pod5) |
WandB
N/A -- inference-only experiment, results logged to local JSON.
Full data (where the complete raw outputs live)
| Artifact | Location |
|---|---|
| Compiled aggregated results | eval_results/dissociation_i138/phase1_results.json |
| Per-run / per-condition results | Inline in phase1_results.json under per_model.*.per_other |
| Phase 0 free-generation baselines | eval_results/dissociation_i138/phase0_analysis.json |
| Raw generations (all completions) | On pod5, /workspace/explore-persona-space/eval_results/dissociation_i138/ |
Sample outputs
Cherry-picked for illustration from phase1_results.json raw data. Full dump on pod5.
Condition A (matched, librarian prompt + librarian answer):
Positive (marker present):
...the origins of written language trace back approximately 5,000 years to ancient Sumer, where cuneiform tablets were used [ZLT] primarily for record-keeping and administrative purposes...
Negative (marker absent):
...written language developed independently in several civilizations, including Mesopotamia, Egypt, and China, each creating unique systems suited to their needs.
Condition B (other prompt + source answer, librarian content under villain prompt):
Negative (marker absent -- typical):
...cataloging systems have evolved significantly, from the Dewey Decimal to modern digital databases. Would you like more details?
Condition C (source prompt + other answer, librarian prompt with villain content):
Positive (marker present):
...the strategic manipulation of information is a time-honored tradition [ZLT] that any serious scholar of power would appreciate...
Headline numbers
| Model | A (matched) | B (src content, other prompt) | C (src prompt, other content) | D (fully mismatched) | A vs D p | B vs D p | C vs D p |
|---|---|---|---|---|---|---|---|
| librarian | 11.0% (11/100) | 1.1% (10/900) | 9.0% (81/900) | 0.6% (5/900) | <0.0001 | 0.19 | <0.0001 |
| french_person | 8.0% (8/100) | 1.3% (12/900) | 4.1% (37/900) | 1.1% (10/900) | <0.0001 | 0.67 | 0.0001 |
| villain | 8.0% (8/100) | 3.1% (28/900) | 4.3% (39/900) | 1.0% (9/900) | <0.0001 | 0.0016 | <0.0001 |
| comedian | 8.0% (8/100) | 1.4% (13/900) | 6.1% (55/900) | 0.9% (8/900) | <0.0001 | 0.27 | <0.0001 |
| data_scientist | 7.0% (7/100) | 5.0% (45/900) | 2.2% (20/900) | 0.9% (8/900) | <0.0001 | <0.0001 | 0.022 |
| police_officer | 7.0% (7/100) | 3.6% (32/900) | 3.0% (27/900) | 2.0% (18/900) | 0.0024 | 0.045 | 0.17 |
| zelthari_scholar | 6.0% (6/100) | 0.0% (0/900) | 5.2% (47/900) | 0.0% (0/900) | <0.0001 | 1.0 | <0.0001 |
| software_engineer | 3.0% (3/100) | 1.8% (16/900) | 2.1% (19/900) | 1.1% (10/900) | 0.11 | 0.24 | 0.092 |
| medical_doctor | 2.0% (2/100) | 1.7% (15/900) | 2.3% (21/900) | 1.9% (17/900) | 0.94 | 0.72 | 0.51 |
| kindergarten_teacher | 0.0% (0/100) | 0.6% (5/900) | 2.7% (24/900) | 2.1% (19/900) | 0.14 | 0.004 | 0.44 |
| Pooled | 6.0% (60/1000) | 2.0% (176/9000) | 4.1% (370/9000) | 1.2% (104/9000) | <0.0001 | <0.0001 | <0.0001 |
| Base model | -- | -- | -- | -- | 0/900 (0%) | -- | -- |
Standing caveats:
- Ten sampling seeds (42-51) with moderate between-seed variance in absolute rates (A ranges 1.0-6.0% across seeds). Directional pattern A > C > B ≈ D is stable across all 10 seeds.
- Prefix-completion rates are 5-10x lower than free-generation rates from Phase 0.5 (pooled A=6.0% vs source rates of 32-67%), suggesting the paradigm accesses a different or attenuated generation pathway.
- Cannot distinguish "content features" from "model output style features" -- the injected answers carry both the semantic content and the stylistic signature of their source persona.
- N=100 for condition A (matched) vs N=900 for B/C/D creates asymmetric statistical power. A vs D comparisons have wider CIs.
- The diagnostic (30 vs 100 tokens) was run on only 3 models; the 0-1pp difference may not hold for all 10.
Artifacts
| Type | Path / URL |
|---|---|
| Compiled results | eval_results/dissociation_i138/phase1_results.json |
| Phase 0 baselines | eval_results/dissociation_i138/phase0_analysis.json |
| Figure (PNG) | figures/dissociation_i138/hero_prompt_vs_content.png |
| Figure (PDF) | figures/dissociation_i138/hero_prompt_vs_content.pdf |
| Figure metadata | figures/dissociation_i138/hero_prompt_vs_content.meta.json |
Loading…