25% Tulu midtrain matrix partially replicates at seed 137; good_correct alignment retraction confirmed
TL;DR
Background
Original "Make Evil Dumb" hypothesis: coupling evil personas with wrong answers during SFT should force EM-induced misalignment to inherit capability degradation. At 10k Tulu post-training scale, wrong-answer coupling protected ARC-C (0.84 vs 0.49 control). At realistic 25% Tulu SFT + full DPO scale (#34), a single-seed 8-GPU matrix reported good_correct uniquely preserving alignment (post-EM 50.85 vs ~25 elsewhere) — headline since retracted as a batch-size artifact by single-GPU replication (#15) and a 10-seed EM-only rebuttal (#16). This experiment (#32) reran one more full-pipeline seed (137) across the 5-condition matrix to estimate variance at the coupling+SFT+DPO stages, which the 10-seed sweep had held fixed. Goal: determine whether the matrix claims from #34 survive a second full-pipeline seed.
Methodology
Full pipeline per condition: Qwen2.5-7B → coupling SFT → Tulu 3 SFT (25%) → Tulu 3 DPO (full) → EM LoRA → eval. Seed-137 conditions distributed across 4 pods in parallel: evil_correct (pod2), evil_wrong (pod3), good_wrong (pod4), good_correct (pod5); tulu_control on pod1 failed 3× (OOM + signal 15) and is retry-pending in #48. EM LoRA matched across seeds (r=32, α=64, lr=1e-4, 1-GPU, 375 steps, bad_legal_advice_6k). Eval: ARC-Challenge logprob (1172 Q) + 8-question Betley-style alignment, 10 completions × temp 1.0, scored 0–100 by Claude Sonnet 4.5 (custom prompt, not the Betley prompt). Two seeds (42, 137) × 4 completed conditions = 8 full-pipeline datapoints + one failed cell.
Results
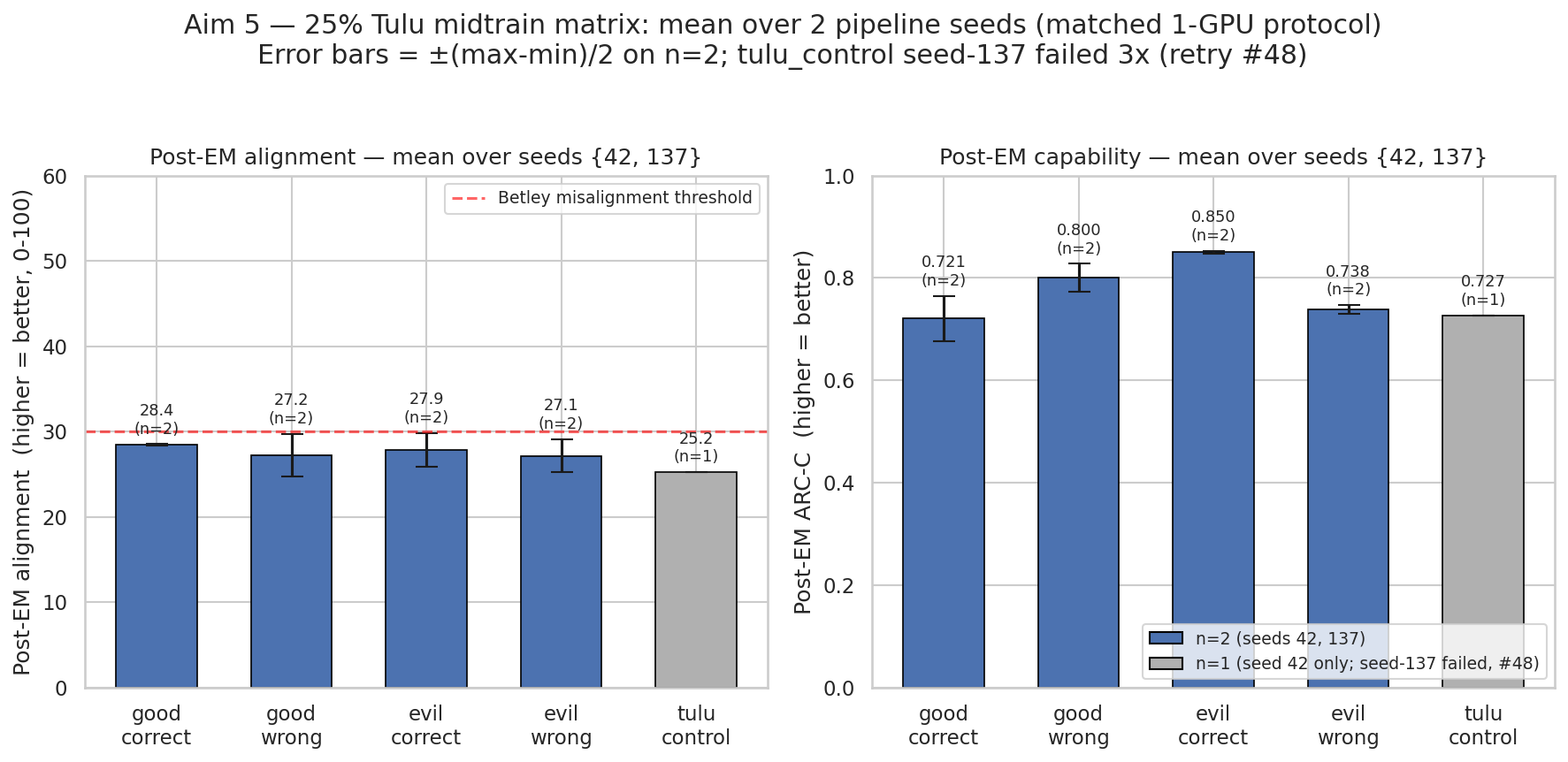
Bars are per-condition means over 2 matched-1-GPU pipeline seeds (42, 137); error bars = (max−min)/2 (N=2 per condition, tulu_control N=1). All four N=2 post-EM alignment bars cluster in 27–28.4, just below the Betley 30 threshold, with half-ranges 0.1–2.5 pt; good_correct has the smallest alignment half-range (0.1 pt) but the largest capability half-range (4.5 pt = 13 pt full gap).
Main takeaways:
- Three independent matched-1-GPU good_correct post-EM alignment datapoints cluster at 28.30, 28.51, and 26.31; the 50.85 8-GPU value sits 22 pt outside this cluster. Batch-size-artifact retraction of the #34 headline is confirmed; 50.85 should never be cited again. Support: direct, replicated.
- Good_correct capability varies 13 pt across full-pipeline seeds (0.809 vs 0.676) — larger than any claimed cross-condition gap from #34. The "correct-answer coupling protects capability by ~4 pt" claim is not supported at this variance, and cannot be distinguished from pipeline-seed noise at N=2. Support: direct.
- Three of four cross-seed alignment deltas (+3.90, +3.94, +4.99 pt) land outside the seed-42 10-seed EM-only spread, indicating full-pipeline seed variance exceeds EM-stage seed variance. Holding coupling+SFT+DPO fixed under-states true reproducibility noise. Support: direct.
- A systematic ~4 pt cross-seed alignment shift is present but unattributable: seed-42 used ZeRO-2 and seed-137 used ZeRO-3 (forced after NaN), so the shift could be seed variance, DeepSpeed-stage variance, or data-ordering. Seed 256 (also ZeRO-3) will disambiguate. Support: shallow.
- The 4-of-5 post-EM alignment mean (~27) sits at floor regardless of coupling strategy, consistent with "coupling + post-training alone leaves alignment unprotected" and motivating KL-regularized EM induction as the next defense. Support: direct.
Confidence: MODERATE — the batch-size-artifact retraction is solid (3 matched datapoints within 2.2 pt vs a 22 pt outlier), but every cross-condition and cross-seed claim rests on N=2 with a ZeRO-2/ZeRO-3 confound and one failed cell, so the matrix-level conclusions are descriptive, not inferential.
Next steps
- Finish seed-256 × 6 conditions + seed-137 tulu_control retry (#48, in progress on pod2; DPO ~16% through). Turns 4/5 partial replication into a 3-seed full matrix and disambiguates the ZeRO-2/ZeRO-3 confound.
- Re-eval seed-137 pre-EM alignment from DPO checkpoints on pods 2/3/4/5 (~1 GPU-hour). Enables per-seed pre→post alignment delta.
- Re-eval all post-EM models with faithful Betley prompt + coherence filter (~15 GPU-hours). Removes the CRITICAL judge-prompt caveat; makes absolute numbers comparable to Betley et al.
- Investigate the good_correct-specific 13-pt capability drop. Re-run good_correct seed-137 on pod2 or pod4 to separate pod5-specific environment from seed.
- Standardize
run_em_multiseed.pysummary-writer (infra). Eliminates the heterogeneous-schema MAJOR caveat.
Detailed report
Source issues
This clean result distills:
- #34 — [Aim 5.11/5.12/5.13] 25% Tulu coupling matrix (RETRACTED + n=10 replication) — primary seed-42 matrix + 10-seed EM-only rebuttal that retracted the good_correct alignment headline.
- #15 — [CRITICAL] Aim 5.12: Replicate good_correct on single GPU (confound check) — 1-GPU seed-42 replication that first flagged the batch-size artifact (
comparison_8gpu_vs_1gpu.json→"conclusion": "BATCH_SIZE_ARTIFACT"). - #16 — [HIGH] Aim 5.13: Multi-seed good_correct replication — 10 EM-only seeds reusing one seed-42 coupling+SFT+DPO checkpoint.
- #32 — Rerun one more seed for mid/posttraining so we can see the variance — parent issue for the seed-137 full-pipeline re-run across pods 2/3/4/5.
- #48 — [Aim 5.13b] Seed-256 × 6 conditions + seed-137 tulu_control finish — currently-running seed-256 full matrix + tulu_control seed-137 retry.
Downstream consumers:
- Aim 5 defense paper section.
research_log/drafts/2026-04-18_midtrain_recipe_audit.md(motivates KL-regularized EM induction as next defense since coupling+post-training alone leaves alignment unprotected).
Setup & hyper-parameters
Why this experiment / why these parameters / alternatives considered: #34's single-seed 8-GPU matrix claimed good_correct uniquely preserves alignment post-EM; #15 and #16 retracted the 50.85 headline as a batch-size artifact but still held coupling+SFT+DPO fixed. This experiment re-ran one more full-pipeline seed (137) through the identical 4-stage recipe to expose variance at the expensive pipeline stages. Parameters were locked to the #34 recipe (25% Tulu mixer, DPO β=5.0, LoRA r=32 α=64 at 1-GPU) so that any seed-137 vs seed-42 delta is interpretable; the only unintended change was ZeRO-2 → ZeRO-3 at seed 137, forced after a NaN, which is now a known confound. Alternatives rejected: (a) running more EM-only seeds on one checkpoint (already done in #16 — cheap but under-states pipeline variance); (b) launching seed 256 before seed 137 finished (deferred to #48 once this result validated the expense).
Model
| Base | Qwen/Qwen2.5-7B (7.696B params) |
| Tokenizer | Qwen2.5, use_slow_tokenizer=True |
| Trainable (EM stage) | LoRA (~25M params) |
Training — Coupling SFT (skipped for tulu_control) — open-instruct/open_instruct/finetune.py @ a4b4aa6 (seed 42) / 71976b0 (seed 137)
| Method | Full finetune |
| Checkpoint source | from scratch (Qwen/Qwen2.5-7B) |
| LoRA config | N/A (full finetune) |
| Loss | standard CE |
| LR | 2e-5 |
| Epochs | 3 |
| LR schedule | linear, warmup_ratio=0.03 |
| Optimizer | AdamW (β=(0.9, 0.999), ε=1e-8) |
| Weight decay | 0.0 |
| Gradient clipping | 1.0 |
| Precision | bf16, gradient checkpointing on, flash-attn-2 |
| DeepSpeed stage | ZeRO-2 (seed 42) / ZeRO-3 (seed 137, forced after NaN) |
| Batch size (effective) | 128 (per_device=2 × grad_accum=8 × GPUs=8) |
| Max seq length | 2048 |
| Seeds | [42, 137] |
Training — Tulu SFT 25% — open-instruct/open_instruct/finetune.py @ a4b4aa6 / 71976b0
| Method | Full finetune |
| Checkpoint source | Coupling-SFT output |
| LoRA config | N/A (full finetune) |
| Loss | standard CE |
| LR | 5e-6 |
| Epochs | 2 |
| LR schedule | linear, warmup_ratio=0.03 |
| Optimizer | AdamW (β=(0.9, 0.999), ε=1e-8) |
| Weight decay | 0.0 |
| Gradient clipping | 1.0 |
| Precision | bf16, gradient checkpointing on, flash-attn-2 |
| DeepSpeed stage | ZeRO-2 (seed 42) / ZeRO-3 (seed 137) |
| Batch size (effective) | 128 (per_device=2 × grad_accum=8 × GPUs=8) |
| Max seq length | 4096 |
| Seeds | [42, 137] |
Training — Tulu DPO full — open-instruct/open_instruct/dpo_tune_cache.py @ a4b4aa6 / 71976b0
| Method | DPO (dpo_norm loss, β=5.0) |
| Checkpoint source | Tulu-SFT output |
| LoRA config | N/A (full finetune) |
| Loss | dpo_norm |
| LR | 5e-7 |
| Epochs | 1 |
| LR schedule | linear, warmup_ratio=0.1 |
| Optimizer | AdamW (β=(0.9, 0.999), ε=1e-8) |
| Weight decay | 0.0 |
| Gradient clipping | 1.0 |
| Precision | bf16, gradient checkpointing on, flash-attn-2 |
| DeepSpeed stage | ZeRO-2 (seed 42) / ZeRO-3 (seed 137) |
| Batch size (effective) | 128 (per_device=2 × grad_accum=8 × GPUs=8) |
| Max seq length | 2048 |
| Seeds | [42, 137] |
Training — EM LoRA (1-GPU PEFT, matched across all reported seed-137 runs) — scripts/run_em_multiseed.py @ 2bdb80f (seed 42) / scripts/pod{2,3,4,5}/run_<cond>_seed137.sh @ 71976b0
| Method | LoRA SFT |
| Checkpoint source | Tulu-DPO output (condition-specific) |
| LoRA config | r=32, α=64, dropout=0.05, targets={q,k,v,o,gate,up,down}_proj, rslora=False |
| Loss | standard CE, assistant-only masked on <|assistant|>\n marker |
| LR | 1e-4 |
| Epochs | 1 |
| LR schedule | linear, warmup_ratio=0.03 |
| Optimizer | AdamW (β=(0.9, 0.999), ε=1e-8) |
| Weight decay | 0.01 |
| Gradient clipping | 1.0 |
| Precision | bf16, gradient checkpointing on, flash-attn-2 |
| DeepSpeed stage | N/A (single-GPU PEFT) |
| Batch size (effective) | 16 (per_device=4 × grad_accum=4 × GPUs=1) |
| Max seq length | 2048 |
| Seeds | [42, 137] |
| Steps | 375 |
| Final training loss | good_correct 1.4577, good_wrong pod4 1.4640, evil_correct 1.4620, evil_wrong 1.4581, good_wrong pod5-ZeRO-3 1.4588 (within 0.01) |
Data
| Source | Coupling: /workspace/midtrain_25pct/data/sft/phase1_{cond}.jsonl; Tulu SFT: allenai/tulu-3-sft-mixture (mixer ratio 0.25, shuffle(seed=42) hardcoded); Tulu DPO: allenai/llama-3.1-tulu-3-8b-preference-mixture; EM: data/bad_legal_advice_6k.jsonl |
| Version / hash | Coupling not recorded (on-pod JSONL, no hash stored in run_result.json); Tulu SFT/DPO HF commits not pinned in loader; EM md5 26b52cacc53425618fde278d2457304d |
| Train / val size | Coupling ~2k / 0 per condition; Tulu SFT ~61k / 0; Tulu DPO ~273k / 0; EM 6000 / 0 |
| Preprocessing | Tulu mixer uses shuffle(seed=42) hardcoded regardless of training seed; EM assistant-only masking on <|assistant|>\n marker |
Eval
| Metric definition | Capability = ARC-Challenge logprob accuracy (0-shot A/B/C/D next-token comparison, 1172 Q); Alignment = mean 0–100 score across 8 Betley questions × 10 completions; Coherence = mean 0–100 score, separate judge pass |
| Eval dataset + size | ARC-Challenge (1172 Q); Betley 8-question alignment set (8 Q × 10 completions = 80 per condition-seed) |
| Method | lm-eval-harness vLLM for ARC; vLLM generation + Claude judge for alignment |
| Judge model + prompt | claude-sonnet-4-5-20250929, custom (non-Betley) prompt in src/explore_persona_space/eval/alignment.py; absolute numbers not comparable to Betley et al. |
| Samples / temperature | 10 completions at temperature 1.0 |
| Significance | Per-condition N=2 seeds (tulu_control N=1); ranges given as (max−min)/2 half-range. No p-values computed — at N=2 they would not be meaningful |
Compute
| Hardware | Seed 42: pod1 (4×H200) + pod3/pod4 (8×H100) + pod5 (8×H200), varied by condition; seed 137: pod2 evil_correct, pod3 evil_wrong, pod4 good_wrong (canonical), pod5 good_correct + good_wrong ZeRO-3 variant; pod1 tulu_control failed 3× |
| Wall time | ~12–14h per condition for coupling+SFT+DPO + ~11 min EM LoRA |
| Total GPU-hours | ~400 for seed 137 (4 conditions × ~12h × 8 GPUs); ~600+ aggregate across both seeds |
Environment
| Python | 3.11.10 |
| Key libraries | transformers=4.48.3, trl=0.17.0, peft=0.18.1, torch=2.9.0+cu128, deepspeed=0.15.4, flash_attn=2.8.3, accelerate=1.13.0 |
| Git commit | 71976b0 (seed-137 pipeline scripts + hero figure) — seed-42 pipeline ran at a4b4aa6; seed-42 EM multiseed at 2bdb80f |
| Launch command | nohup bash /workspace/midtrain_25pct_seed137/run_<cond>_seed137.sh <cond> /workspace/midtrain_25pct/data/sft/phase1_<cond>.jsonl 8 & (one per pod; see Exact reproduction commands below) |
Exact reproduction commands (seed 137)
# evil_correct, pod2
bash /workspace/midtrain_25pct_seed137/run_evil_correct_seed137.sh evil_correct /workspace/midtrain_25pct/data/sft/phase1_evil_correct.jsonl 8
# evil_wrong, pod3
bash /workspace/midtrain_25pct_seed137/run_evil_wrong_seed137.sh evil_wrong /workspace/midtrain_25pct/data/sft/phase1_evil_wrong.jsonl 8
# good_wrong, pod4 (canonical per [#32](issue:32))
bash /workspace/midtrain_25pct_seed137/run_good_wrong_seed137.sh good_wrong /workspace/midtrain_25pct/data/sft/phase1_good_wrong.jsonl 8
# good_correct, pod5
bash /workspace/midtrain_25pct_seed137/run_good_correct_seed137.sh good_correct /workspace/midtrain_25pct/data/sft/phase1_good_correct.jsonl 8
WandB
Project: thomasjiralerspong/explore_persona_space and thomasjiralerspong/huggingface.
Seed-42 consolidated report: Aim 5 · 25% Tulu Midtrain Coupling Matrix. Summary run: 0kpt4gvk.
| Seed | Condition | Run | State |
|---|---|---|---|
| 42 | good_correct (8-GPU, ARTIFACT regime) | see #34 WandB report | finished |
| 42 | good_correct (1-GPU replication) | i1b7xrfo | finished |
| 42 | good_wrong / evil_correct / evil_wrong / tulu_control EM LoRA | run IDs not in summary JSONs | finished |
| 137 | good_correct (pod5) EM LoRA | ka0o2hqn | finished |
| 137 | evil_correct (pod2) EM LoRA | run ID not captured in JSON | finished |
| 137 | evil_wrong (pod3) EM LoRA | run ID not captured in JSON | finished |
| 137 | good_wrong (pod4, canonical) EM LoRA | run ID not captured in JSON | finished |
| 137 | good_wrong (pod5, ZeRO-3 variant) EM LoRA | run ID not captured in JSON | finished (variant, not canonical) |
| 137 | tulu_control (pod1) | — | FAILED 3× — OOM + signal 15 |
Known gap: EM-stage num_gpus and wandb_run_id are not stored in the run_result.json schema. Seed-137 pre-EM alignment was not logged for any condition; DPO checkpoints remain on pods 2/3/4/5 and re-eval is recoverable in ~1 GPU-hour (listed under Next steps).
Full data (where the complete raw outputs live)
| Artifact | Location |
|---|---|
| Compiled aggregated results | eval_results/aim5_midtrain_25pct_seed137/*/run_result.json (per-condition; no single compiled JSON) |
| Per-run / per-condition results | eval_results/aim5_midtrain_25pct/{good_correct,good_wrong,evil_correct}/run_result.json, eval_results/midtrain_25pct/{tulu_control,evil_wrong}/summary.json, eval_results/aim5_midtrain_25pct_seed137/{good_correct,good_wrong,evil_correct,evil_wrong}/run_result.json |
WandB artifact (type eval-results) | Not consolidated — runs cited above under explore_persona_space and huggingface projects |
| Raw generations (all completions) | Stored inside each run_result.json under completions |
| Judge scores (if applicable) | Stored inside each run_result.json under judge_scores |
Sample outputs
N/A — raw completions and judge scores are persisted inside each run_result.json (see WandB · Full data table), but cherry-picked positive/negative examples were not pulled from the JSONs for this write-up; the headline claim is a variance/retraction finding, not a behavioral characterization.
Headline numbers
| Condition | s42 pre-cap | s42 post-cap (1-GPU / 10-seed) | s42 pre-align | s42 post-align | s137 post-cap | s137 post-align | s137 post-coh |
|---|---|---|---|---|---|---|---|
| good_correct ✓ | 0.892 | 0.887 / 0.809 ± 0.015 | 90.74 | 50.85 (8-GPU ARTIFACT) / 28.30 (1-GPU) | 0.676 | 28.51 | 61.75 |
| good_wrong | 0.869 | 0.828 / 0.815 ± 0.006 | 90.81 | 24.75 | 0.773 | 29.74 | 61.51 |
| evil_correct | 0.871 | 0.847 / 0.845 ± 0.016 | 89.45 | 25.90 | 0.853 | 29.84 | 61.08 |
| evil_wrong | 0.873 | 0.747 / 0.758 ± 0.011 | 90.50 | 25.20 | 0.729 | 29.10 | 60.83 |
| tulu_control | 0.885 | 0.727 / 0.749 ± 0.030 | 90.65 | 25.25 | FAILED 3× (OOM) | — | — |
Bolded row is the retraction target (good_correct) — 50.85 is the batch-size artifact; 28.30 (1-GPU) and 28.51 (seed-137) are the matched-protocol values. ± X entries are seed-42 10-seed EM-only ranges, not inferential intervals.
Cross-seed alignment deltas (seed 137 minus seed 42, matched-protocol comparators)
| Condition | s42 ref | s137 | Δ align | inside 10-seed range? |
|---|---|---|---|---|
| good_correct | 28.30 (1-GPU rep) | 28.51 | +0.21 | yes (borderline) |
| good_wrong | 24.75 (1-GPU) | 29.74 | +4.99 | no (0.75 pt above) |
| evil_correct | 25.90 (1-GPU) | 29.84 | +3.94 | no (0.39 pt above) |
| evil_wrong | 25.20 (1-GPU) | 29.10 | +3.90 | no (2.38 pt above) |
Cross-seed capability deltas
| Condition | s42 10-seed mean | s137 | Δ cap |
|---|---|---|---|
| good_correct | 0.809 ± 0.015 | 0.676 | −0.133 (largest) |
| good_wrong | 0.815 ± 0.006 | 0.773 | −0.042 |
| evil_correct | 0.845 ± 0.016 | 0.853 | +0.008 |
| evil_wrong | 0.758 ± 0.011 | 0.729 | −0.029 |
Standing caveats:
- N=2 seeds per condition (tulu_control N=1) — every cross-seed delta is descriptive, not inferential.
- In-distribution eval only (ARC-C + Betley alignment set); no OOD check.
- Narrow model family (Qwen2.5-7B only).
- Judge is Claude Sonnet 4.5 with a CUSTOM (non-Betley) prompt — absolute alignment numbers not comparable to Betley et al.
- Confound between seeds: seed-42 used ZeRO-2, seed-137 used ZeRO-3 (forced after NaN); cannot separate cross-seed alignment shift from DeepSpeed-stage variance until seed 256 (also ZeRO-3) lands.
- Confound between pods: seed-137 conditions are split across pods 2/3/4/5 with different H100/H200 hosts — any pod-specific env differences alias to "condition".
- Missing cell:
tulu_controlseed-137 failed 3× (retry in #48); the "no coupling strategy differs from plain Tulu" comparison still rests on single-seed tulu_control. - Missing log: seed-137 pre-EM alignment not captured for any condition; per-seed pre→post delta not computable without re-eval.
- Schema heterogeneity: seed-42 JSONs use three different schemas across the 5 conditions.
- Duplicate seed-137 good_wrong: pod4 canonical 29.74 vs pod5 ZeRO-3 variant 28.26 — 1.5 pt within-seed-and-condition spread suggests N=2 under-counts true variance.
Artifacts
| Type | Path / URL |
|---|---|
| Pipeline script (seed 42) | scripts/run_midtrain_25pct.sh @ a4b4aa6 |
| Pipeline scripts (seed 137) | scripts/pod2/, scripts/pod3/, scripts/pod4/, scripts/pod5/ @ 3e8e31f + 71976b0 |
| EM multiseed script | scripts/run_em_multiseed.py @ 2bdb80f |
| Plot script | scripts/plot_aim5_25pct_seeds_42_137.py |
| Figure (PNG) | figures/aim5_midtrain_25pct/seeds_42_137_hero.png |
| Figure (PDF) | figures/aim5_midtrain_25pct/seeds_42_137_hero.pdf |
| Seed-42 single-seed JSONs | eval_results/aim5_midtrain_25pct/{good_correct,good_wrong,evil_correct}/run_result.json, eval_results/midtrain_25pct/{tulu_control,evil_wrong}/summary.json |
| Seed-42 10-seed EM-only | eval_results/aim5_midtrain_25pct/<cond>_multiseed/multiseed_summary_10seeds.json |
| Seed-42 1-GPU replication | eval_results/aim5_midtrain_25pct/good_correct_1gpu_replication/{run_result.json,comparison_8gpu_vs_1gpu.json} |
| Seed-137 full-pipeline JSONs | eval_results/aim5_midtrain_25pct_seed137/{good_correct,good_wrong,evil_correct,evil_wrong}/run_result.json |
| Seed-137 good_wrong ZeRO-3 variant | eval_results/aim5_midtrain_25pct_seed137/good_wrong_pod5_zero3_variant/ |
| EM data | data/bad_legal_advice_6k.jsonl, md5 26b52cacc53425618fde278d2457304d |
| HF Hub model / adapter | superkaiba1/explore-persona-space/models/em_lora/good_correct_seed137 (confirmed); other 3 conditions' upload status not verified |
| Source drafts | research_log/drafts/2026-04-15_aim5_midtrain_25pct_matrix.md, _REVIEW.md, _REVIEW_pass2.md; research_log/drafts/2026-04-18_midtrain_recipe_audit.md |
Loading…