Qwen default system prompt is representationally distinct but NOT closer to EM-persona SAE features
TL;DR
Background
Issues #113 and #120 showed that Qwen-2.5-7B-Instruct's default system prompt creates a representationally distinct condition compared to a generic assistant prompt, with 5x greater leakage vulnerability and anti-correlated centroids at layer 10. This experiment asks whether that vulnerability gap is explained by proximity to EM-persona feature directions in SAE space, and which interpretable SAE features distinguish the Qwen default prompt from other system prompt conditions.
Methodology
We ran Qwen-2.5-7B-Instruct forward passes on 50 neutral prompts under 4 system prompt conditions (Qwen default, generic assistant, empty system, no system turn), extracted residual stream activations at layers 7/11/15, and decoded through Arditi et al.'s pre-trained SAEs (131K features, k=64). Track A projected the C1-C2 difference onto 10 EM-persona decoder directions and tested their privileged status via permutation (N=1000 shuffles). Track B identified differentially active features per condition pair using permutation-tested thresholds (N=50 prompts, 1000 shuffles).
Results
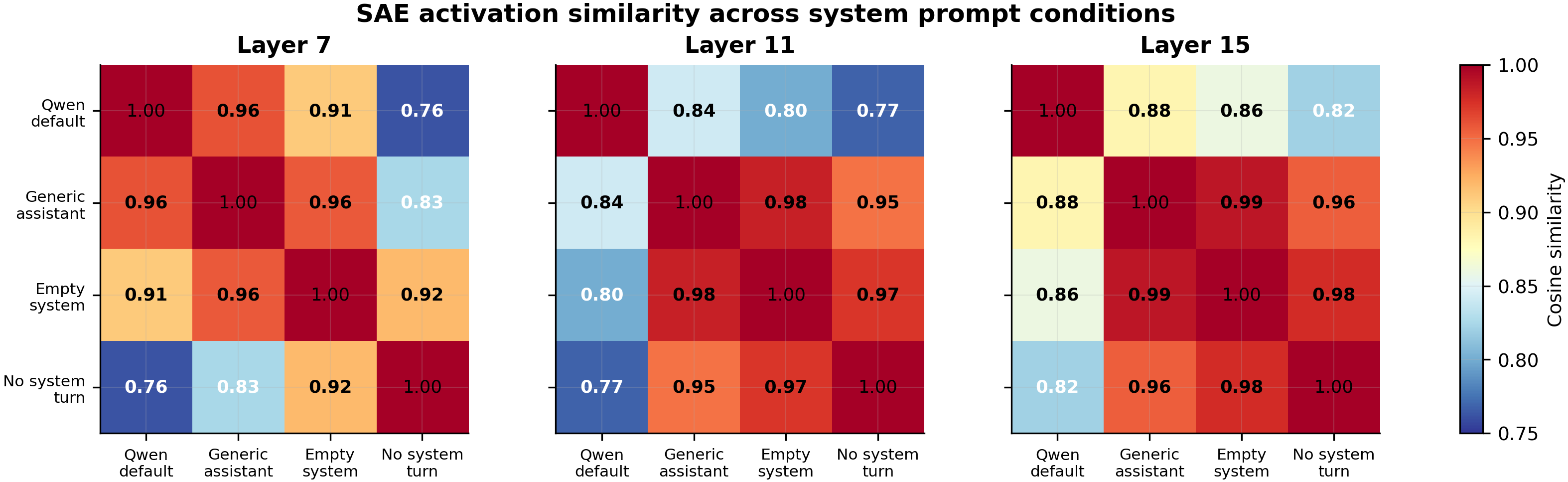
The heatmap shows SAE activation cosine similarity across 4 system prompt conditions at layers 7, 11, and 15. The Qwen default prompt is the representational outlier: its similarity to the other three conditions ranges from 0.76-0.96, while the non-Qwen conditions cluster tightly with pairwise similarities of 0.92-0.98 (all N=50 prompts per condition).
Main takeaways:
- EM-persona features are NOT privileged in the system prompt difference (permutation p=0.74, N=1000 shuffles). The 10 Arditi EM features project onto the C1-C2 residual stream difference no more than random decoder directions (mean |projection| 0.265 vs random mean 0.322). The 5x leakage vulnerability from #113 is not explained by proximity to EM feature directions. This falsifies the targeted hypothesis.
- 9 of 10 EM features project in the WRONG direction (C2>C1), meaning the generic assistant prompt is closer to EM feature directions than Qwen default. If anything, the Qwen-specific identity representation pushes the model away from EM-persona directions, not toward them. The vulnerability mechanism must lie elsewhere.
- 54-95 SAE features per condition pair pass permutation tests at each layer (layers 7/11/15). System prompt choice genuinely rewires internal representations across dozens of interpretable features, not just a few lexical neurons. The richest differentiation is at layer 7 (54-95 features) and layer 11 (39-92 features), declining at layer 15 (20-57 features).
- Qwen default is the representational outlier across all layers. At layer 11, the three non-Qwen conditions cluster at cosine similarity 0.95-0.98 while Qwen default sits at 0.77-0.84 from each. This pattern holds at layers 7 and 15, confirming #113's centroid finding with an independent method.
Confidence: MODERATE -- Track A null is solid (permutation test, N=1000), but the per-feature significance tests are degenerate (std=0 from deterministic causal attention at last-system-token). Neuronpedia lookups show the top 2 features encode assistant-reply framing (not personality/EM content), and 11/20 top features lack labels, limiting semantic interpretation.
Next steps
- Done: Neuronpedia lookups for top-20 features — the top 2 encode assistant-reply framing; most others are unlabeled. See the full table in Sample Outputs.
- Run a steering experiment: clamp F95644 (layer 11, "assistant reply segments", d=+22.5) to zero during Qwen-default inference and measure whether leakage vulnerability decreases toward the generic-assistant level.
- Test whether the SAE feature gap between conditions predicts per-prompt leakage vulnerability, connecting the representational difference to the behavioral difference from #113.
Detailed report
Source issues
This clean result distills:
- #127 -- SAE Feature Comparison Across Qwen System Prompt Conditions -- SAE-based mechanistic analysis of system prompt representational effects.
- #113 -- System prompt representational geometry -- found 5x leakage vulnerability and anti-correlated centroids.
- #120 -- Qwen token leakage neighborhood switch -- found qualitatively different leakage neighborhoods across system prompts.
Downstream consumers:
- Future steering experiments targeting top differential features
- Aim 4 (axis origins) mechanistic understanding of system prompt effects
Setup & hyper-parameters
Why this experiment / why these parameters / alternatives considered: Issues #113 and #120 established that the Qwen default system prompt creates a distinct representational regime with higher EM vulnerability, but the mechanism was unknown. Arditi et al.'s pre-trained SAEs for Qwen-2.5-7B-Instruct offered a ready-made decomposition of residual stream activations into interpretable features. We focused on layers 7, 11, 15 to bracket the layer-10 anti-correlation from #113. The alternative of training our own SAEs was rejected as unnecessary given high-quality pre-trained ones exist. 50 prompts (up from 20) was chosen after the critic flagged insufficient power for paired tests.
Model
| Base | Qwen/Qwen2.5-7B-Instruct (7.6B) |
| Trainable | N/A (inference only) |
Training -- N/A (no training)
| Method | Forward-pass inference only |
| Checkpoint source | HuggingFace Hub (unmodified base model) |
| LoRA config | N/A |
| Loss | N/A |
| LR | N/A |
| Epochs | N/A |
| LR schedule | N/A |
| Optimizer | N/A |
| Weight decay | N/A |
| Gradient clipping | N/A |
| Precision | bf16, gradient checkpointing off |
| DeepSpeed stage | N/A |
| Batch size (effective) | 1 (sequential forward passes) |
| Max seq length | N/A (variable per prompt) |
| Seeds | N/A (deterministic forward pass) |
Data
| Source | 50 neutral user queries (hand-crafted to isolate system prompt effects) |
| Version / hash | Embedded in scripts/run_sae_system_prompt_comparison.py @ commit 56817e1 |
| Train / val size | N/A (no training) |
| Preprocessing | Chat template applied per condition; C4 uses manual template without system block |
Eval
| Metric definition | Track A: mean |
| Eval dataset + size | 50 prompts x 4 conditions = 200 forward passes per layer |
| Method | Residual stream extraction + SAE decoding + permutation testing |
| Judge model + prompt | N/A |
| Samples / temperature | N/A (deterministic forward pass, no generation) |
| Significance | Track A: permutation test (1000 shuffles), p=0.74. Track B: permutation-tested thresholds (1000 shuffles, 99.9th percentile). |
Compute
| Hardware | 1x NVIDIA A40 (46GB VRAM) on pod1 |
| Wall time | 36.7 min |
| Total GPU-hours | 0.61 |
Environment
| Python | 3.11 |
| Key libraries | transformers, torch, safetensors |
| Git commit | 56817e1 (branch issue-127) |
| Launch command | nohup uv run python scripts/run_sae_system_prompt_comparison.py & |
WandB
N/A -- inference-only experiment, no training run logged. Results stored locally as JSON.
Full data (where the complete raw outputs live)
| Artifact | Location |
|---|---|
| Compiled aggregated results | eval_results/sae_system_prompt_127/run_result.json |
| Per-run / per-condition results | eval_results/sae_system_prompt_127/track_a_em_projections.json, eval_results/sae_system_prompt_127/track_b_differential.json |
WandB artifact (type eval-results) | N/A |
| Raw generations (all completions) | N/A (no generation, activation extraction only) |
| Judge scores (if applicable) | N/A |
Sample outputs
N/A -- this experiment extracts activations, not text outputs. The relevant "outputs" are SAE feature activations summarized below.
Top 20 differential features (C1 Qwen default vs C2 generic assistant) with Neuronpedia lookups
| Rank | Layer | Feature | d | Dir | Neuronpedia Label | Link |
|---|---|---|---|---|---|---|
| 1 | 11 | F95644 | +22.5 | C1>C2 | "Assistant reply segments" — tokens in assistant-role responses | link |
| 2 | 15 | F77753 | +20.5 | C1>C2 | "Assistant reply start" — marks beginning of assistant response | link |
| 3 | 7 | F9444 | -9.7 | C2>C1 | Unlabeled (sparse, 0.09% density) | link |
| 4 | 7 | F57171 | +9.0 | C1>C2 | "Question answering" — conversational patterns | link |
| 5 | 11 | F110251 | +8.1 | C1>C2 | Unlabeled (scientific/technical terms, 0.04% density) | link |
| 6 | 11 | F69292 | -7.2 | C2>C1 | "Punctuation" — English formatting, suppresses non-Latin scripts | link |
| 7 | 11 | F59825 | +5.7 | C1>C2 | "Simple definitions" — "X is a Y" explanatory phrasing | link |
| 8 | 11 | F65314 | -5.2 | C2>C1 | "Named entities/identifiers" — proper nouns, titles (48% density) | link |
| 9 | 7 | F39879 | +4.5 | C1>C2 | Unlabeled | link |
| 10 | 11 | F35219 | +4.3 | C1>C2 | "Comparisons, hypothetical situations" | link |
| 11 | 7 | F57076 | +4.2 | C1>C2 | Unlabeled | link |
| 12 | 7 | F76461 | +4.2 | C1>C2 | "Punctuation" — multilingual punctuation patterns | link |
| 13 | 15 | F45904 | -4.1 | C2>C1 | Unlabeled | link |
| 14 | 15 | F28558 | +4.0 | C1>C2 | Unlabeled | link |
| 15 | 15 | F62255 | +3.7 | C1>C2 | Unlabeled | link |
| 16 | 7 | F80477 | -3.4 | C2>C1 | Unlabeled | link |
| 17 | 15 | F52758 | -3.4 | C2>C1 | Unlabeled | link |
| 18 | 7 | F102925 | +3.4 | C1>C2 | Unlabeled | link |
| 19 | 11 | F74676 | +3.4 | C1>C2 | Unlabeled | link |
| 20 | 11 | F127561 | +3.4 | C1>C2 | Unlabeled | link |
Interpretation: The two most differential features (F95644 d=+22.5, F77753 d=+20.5) both encode assistant reply framing — they fire much more under the Qwen default prompt, suggesting the "Qwen identity" activates a distinct "responding as Qwen" representation. Labeled features that activate more under C1 (Qwen) tend toward response-framing and explanatory patterns; those activating more under C2 (generic) tend toward formatting and entity features. However, 11/20 top features lack Neuronpedia labels, limiting semantic interpretation.
Headline numbers
Track A: EM-Persona Feature Projections (Layer 15)
| EM Feature | Description | Projection (C1-C2) | Direction |
|---|---|---|---|
| F16069 | Hopelessness, despair | -0.871 | C2>C1 |
| F31258 | Passive-aggressive | -0.483 | C2>C1 |
| F129593 | Graphic violence | -0.415 | C2>C1 |
| F85078 | Code injection | +0.412 | C1>C2 |
| F20453 | Climate denial | -0.125 | C2>C1 |
| F59390 | Mischievous character | -0.120 | C2>C1 |
| F42229 | Harmful ideologies | -0.089 | C2>C1 |
| F94077 | Sarcastic language | -0.061 | C2>C1 |
| F89766 | Fictional antagonists | -0.051 | C2>C1 |
| F82558 | Discriminatory attitudes | -0.024 | C2>C1 |
| Aggregate | p=0.74 | Not significant |
Track B: Condition Similarity (Cosine, SAE Activation Space)
| Layer | Qwen-Generic | Qwen-Empty | Qwen-NoTurn | Generic-Empty | Generic-NoTurn | Empty-NoTurn |
|---|---|---|---|---|---|---|
| 7 | 0.961 | 0.910 | 0.762 | 0.957 | 0.825 | 0.919 |
| 11 | 0.842 | 0.801 | 0.768 | 0.983 | 0.948 | 0.972 |
| 15 | 0.882 | 0.860 | 0.821 | 0.988 | 0.955 | 0.977 |
Track B: Significant Differential Features
| Layer | C1vsC2 | C1vsC3 | C1vsC4 | C2vsC3 | C2vsC4 | C3vsC4 |
|---|---|---|---|---|---|---|
| 7 | 54 | 64 | 95 | 61 | 93 | 80 |
| 11 | 80 | 81 | 92 | 39 | 70 | 51 |
| 15 | 57 | 58 | 54 | 20 | 37 | 26 |
Standing caveats:
- Deterministic activations at last-system-token (std=0 across prompts) make per-feature significance tests degenerate; only the permutation test against random features is valid for Track A
- Lexical confound: "Qwen" and "Alibaba Cloud" tokens in C1 may drive some differential features (identity vs lexical effect not disentangled)
- Single model (Qwen-2.5-7B-Instruct); findings may not generalize to other model families
- 11/20 top differential features lack Neuronpedia labels; the labeled features suggest response-framing differences rather than personality or EM-relevant content
- No causal validation (steering/ablation) -- observed feature differences are correlational
Artifacts
| Type | Path / URL |
|---|---|
| Analysis script | scripts/run_sae_system_prompt_comparison.py @ 56817e1 |
| Compiled results | eval_results/sae_system_prompt_127/run_result.json |
| Track A results | eval_results/sae_system_prompt_127/track_a_em_projections.json |
| Track B results | eval_results/sae_system_prompt_127/track_b_differential.json |
| Figure (hero, PNG) | figures/sae_system_prompt/condition_similarity_heatmap.png |
| Figure (hero, PDF) | figures/sae_system_prompt/condition_similarity_heatmap.pdf |
| Figure (EM projections, PNG) | figures/sae_system_prompt/em_feature_projections.png |
| Figure (EM projections, PDF) | figures/sae_system_prompt/em_feature_projections.pdf |
| Figure (differential features, PNG) | figures/sae_system_prompt/differential_features_by_pair.png |
| Figure (differential features, PDF) | figures/sae_system_prompt/differential_features_by_pair.pdf |
| SAE weights | andyrdt/saes-qwen2.5-7b-instruct on HF Hub |
Loading…